24届秋招Java后端面试合集
前言
是的,你没看错,这是24届秋招的面试记录,面试的时候就想写了,一直鸽到现在,主要还是懒。
以下为去年实验室面试时的实际经历,只记录了前面的面试,后面因为有点拘谨,就没有记录了。
才疏学浅,如有解答错误,敬请指正。
小建议
本文篇幅过长,电脑端可修改目录样式食用
1 | #aside-content .card-widget { |
淘天
项目中的服务注册发现怎么实现
答:使用Nacos作为服务注册发现中心,通过在各服务导入所需的注册或发现依赖,再在配置里配置好服务名,Nacos地址之类的。
Nacos服务注册与发现
Nacos服务注册与发现
1. 搭建Nacos Server
首先,需要搭建一个Nacos Server。可以从Nacos官网下载最新版本的Nacos Server,或者使用Docker来快速启动Nacos服务。
1 | docker run -d --name nacos -e MODE=standalone -p 8848:8848 nacos/nacos-server |
上述命令会以单机模式启动一个Nacos服务,监听在本地的8848端口。
2. 服务注册与发现
2.1 添加依赖
在pom.xml中添加Nacos的Spring Cloud依赖:
1 | <dependency> |
2.2 配置Nacos
在application.yml或application.properties中配置Nacos服务器地址:
1 | spring: |
2.3 启用服务注册与发现
在Spring Boot的主类中,添加@EnableDiscoveryClient注解,启用服务注册与发现功能:
1 | import org.springframework.boot.SpringApplication; |
这样,服务启动时会自动向Nacos Server进行注册。
2.4 服务消费者调用示例
一个服务消费者可以通过RestTemplate或Feign客户端来调用已经注册到Nacos的服务。
在启动类中配置RestTemplate:
1 | import org.springframework.cloud.client.loadbalancer.LoadBalanced; |
在服务调用处使用RestTemplate访问其他服务:
1 | import org.springframework.web.bind.annotation.GetMapping; |
3. 动态配置管理
Nacos也支持集中化的配置管理,可以在Nacos控制台中创建或管理配置,然后在应用中使用这些配置。
3.1 添加依赖
在pom.xml中添加配置管理的依赖:
1 | <dependency> |
3.2 配置Nacos
在application.yml中,配置Nacos的配置管理服务地址:
1 | spring: |
3.3 使用动态配置
在Nacos管理控制台中添加一个配置项,如dataId为your-service-name.yml,并添加内容:
1 | custom: |
然后在代码中使用@Value或@ConfigurationProperties来引用配置:
1 | import org.springframework.beans.factory.annotation.Value; |
4. 启动项目和测试
- 启动Nacos Server。
- 启动Spring Boot项目,服务会自动注册到Nacos。
- 通过浏览器或Postman等工具访问服务接口,验证服务注册和动态配置的功能。
Nacos服务注册与发现的原理
Nacos服务注册与发现的原理
1. 服务注册
服务注册的目的是将服务实例的信息(如服务名称、IP 地址、端口号等)保存到服务注册中心,以便其他服务能够找到它。
- 服务实例启动: 微服务实例启动时,会将自身的元数据信息(如服务名、IP、端口、实例 ID、健康检查地址等)注册到 Nacos 服务器。
- 注册过程: 服务实例通过 HTTP 或者 gRPC 调用 Nacos 提供的 API,将服务元数据发送到 Nacos 服务器。Nacos 会将这些信息保存在内存中,并持久化到存储中(如 MySQL 等)。
- 心跳检测: 服务实例定期向 Nacos 服务器发送心跳请求,表明自己仍然是健康的、可用的。Nacos 服务器通过心跳检测机制维护实例的存活状态。如果 Nacos 在一定时间内没有收到某个服务实例的心跳请求,则认为该实例不可用,并从注册表中移除该实例。
2. 服务发现
服务发现的目的是使服务消费者能够找到服务提供者,以便进行远程调用。
- 服务消费者获取服务列表: 当某个服务消费者需要调用某个服务时,会向 Nacos 服务器查询服务列表。Nacos 服务器根据消费者的请求返回相应的服务实例列表,包括 IP 地址、端口号等信息。
- 负载均衡: 客户端会根据获取的服务列表进行本地的负载均衡(如随机、轮询等),选择一个可用的服务实例进行调用。Nacos 也支持客户端和服务端的负载均衡策略。
- 动态更新: Nacos 客户端会通过长轮询或者推送机制实时监听服务列表的变化。当有服务实例上线、下线或不可用时,Nacos 服务器会通知客户端更新其本地缓存的服务列表。
3. 数据存储与一致性
- 数据存储: Nacos 将服务元数据存储在内存中,并且支持将数据持久化到外部数据库(如 MySQL)中。通过这种方式,Nacos 既能够提供高效的内存存取性能,又能确保数据的持久性。
- 数据一致性: Nacos 使用基于 Raft 协议的集群模式来确保数据一致性。Nacos 集群中的节点通过 Raft 协议选举出一个 Leader,Leader 负责处理客户端的写请求,并将数据同步到 Follower 节点,确保集群中的数据一致。
4. 健康检查
- 客户端主动模式: Nacos 客户端定期向 Nacos 服务器发送心跳请求,表明自身状态。
- 服务端被动模式: Nacos 服务器支持对服务实例的健康检查,包括 TCP、HTTP 等多种方式。如果某个服务实例未通过健康检查,Nacos 会将该实例标记为不可用。
5. 服务分组与命名空间
- 服务分组: Nacos 支持对服务进行分组管理,允许用户根据不同的环境(如开发、测试、生产)对服务进行隔离。
- 命名空间: Nacos 提供命名空间功能,用于多租户隔离和不同环境的区分。每个命名空间有独立的服务列表和配置信息。
项目实现了负载均衡吗,说说负载均衡在客户端和服务端的优劣
答:使用了Ribbon进行负载均衡(具体不太记得了)
Ribbon 实现负载均衡的机制
Ribbon 实现负载均衡的机制
获取服务实例列表:
- Ribbon 客户端启动时,会从服务注册中心(如 Eureka 或 Nacos)拉取服务实例列表。这个列表包含所有注册的、可用的服务实例的详细信息(如服务名、IP、端口等)。
- Ribbon 会将这些服务实例信息缓存到本地,并根据配置的策略对其进行负载均衡。
选择负载均衡策略:
- Ribbon 提供了多种内置的负载均衡策略(例如轮询、随机、加权响应时间、最小并发等)。用户可以选择使用这些内置策略,也可以自定义策略。
- 这些策略被封装成策略类,如
RoundRobinRule、RandomRule、WeightedResponseTimeRule等,每个策略类都实现了IRule接口。 - Ribbon 使用负载均衡规则类(Rule Class)来定义具体的负载均衡算法。
执行负载均衡策略:
- 当客户端需要调用某个服务时,Ribbon 会通过选择的负载均衡策略从本地缓存的服务实例列表中挑选一个实例。
- 例如,如果使用的是轮询策略(
RoundRobinRule),Ribbon 会依次选择下一个服务实例;如果使用的是随机策略(RandomRule),Ribbon 会从可用的服务实例中随机选择一个。
发起请求:
- Ribbon 选定一个服务实例后,客户端会直接向该实例发起请求。
- 如果请求成功,则将结果返回给应用程序。如果请求失败,Ribbon 会根据配置的重试策略,选择其他服务实例进行重试。
Ribbon 的内置负载均衡策略
Ribbon 的内置负载均衡策略
轮询(RoundRobinRule):
- 轮询策略是最常用的一种负载均衡算法。它依次选择服务实例列表中的每一个实例进行调用,循环使用。
- 在每次请求时,Ribbon 会维护一个索引指针指向当前使用的实例,并在使用后将指针指向下一个实例。
随机(RandomRule):
- 随机策略是从服务实例列表中随机选择一个实例进行请求。
- 这种策略在某些场景下能够平衡负载,因为它不会固定地选择某个顺序,能够更均匀地分配请求。
加权响应时间(WeightedResponseTimeRule):
- 根据服务实例的响应时间来分配请求。Ribbon 会动态计算每个实例的平均响应时间,响应时间短的实例被赋予更高的权重。
- Ribbon 选择权重较高的实例,以提高整体系统的响应速度。
最小并发(BestAvailableRule):
- 优先选择当前并发请求数最少的服务实例,能够在一定程度上避免压力集中在某些实例上。
- 这种策略在集群中服务实例性能差异较大时有较好的效果。
区域亲和性(ZoneAvoidanceRule):
- 根据服务实例所在的区域(如机房、数据中心等)进行选择。首先选择本地区域内可用的实例,当本地区域的实例不可用时,选择其他区域的实例。
- 此策略可以最大限度减少跨区域的网络请求延迟。
可用性过滤(AvailabilityFilteringRule):
- 过滤掉那些由于多次访问失败而被标记为 “断路器跳闸” 状态的实例,并过滤掉并发请求数量超过阈值的实例。
客户端负载均衡和服务端负载均衡
客户端负载均衡
定义:
客户端负载均衡(Client-side Load Balancing)是指负载均衡逻辑在客户端应用程序中实现。客户端会直接获取服务实例列表,并根据选定的负载均衡策略(如轮询、随机等)选择一个合适的服务实例进行调用。Ribbon 是一种典型的客户端负载均衡工具。
优点:
- 更好的灵活性和可控性:
客户端可以根据特定的业务需求自定义负载均衡策略,如自定义请求分配规则、故障处理机制、重试策略等。每个客户端可以拥有自己的负载均衡策略,从而实现更细粒度的控制。 - 降低服务端负载:
客户端直接处理负载均衡,服务端不需要额外的负载均衡设备或软件来处理请求分发,从而减少了服务端的压力和单点故障的风险。 - 动态性强:
客户端能够实时获取和更新服务实例列表,适应服务实例的动态变化,如服务的上下线或不可用情况。因此,它能够更快地对服务实例的变化做出响应。 - 不需要额外的基础设施:
无需在网络架构中增加额外的负载均衡设备(如硬件或软件负载均衡器),降低了部署和运维成本。
缺点:
- 增加客户端的复杂性和资源消耗:
负载均衡逻辑运行在客户端,需要客户端应用程序维护服务实例列表、执行健康检查、选择负载均衡策略等,这会增加客户端的复杂性,并消耗更多的内存和计算资源。 - 服务实例列表更新延迟:
虽然客户端可以实时更新服务实例列表,但在大规模分布式系统中,服务注册中心的数据同步可能会有延迟,这可能导致客户端在短时间内获取到不一致的服务状态。 - 缺乏集中管理:
每个客户端维护自己的负载均衡逻辑和服务列表,这可能导致难以进行统一的策略管理和调整。如果策略需要更改,可能需要对每个客户端进行更新和配置。
服务端负载均衡
定义:
服务端负载均衡(Server-side Load Balancing)是指将所有的请求先发送到一个负载均衡器(如 Nginx、HAProxy、F5、AWS ELB 等),然后由该负载均衡器根据一定的策略将请求分发到后端的服务实例上。
优点:
- 集中化管理和配置:
服务端负载均衡器能够集中管理请求的分发策略、故障处理、健康检查等,易于进行统一的配置和监控。这种集中管理有助于在大规模部署中更好地控制和优化系统性能。 - 减少客户端的复杂性:
客户端不需要关心具体的服务实例位置和状态,只需请求负载均衡器即可。这样,客户端逻辑简单,减少了资源消耗和开发复杂度。 - 更好的可扩展性:
服务端负载均衡器通常具有较强的处理能力和扩展性,能够在高并发场景下均衡地分配请求,避免单个服务实例被过载。 - 更高级的路由和控制功能:
负载均衡器可以提供更高级的功能,例如基于内容的路由、SSL 终止、基于权重的负载分发、会话保持、请求重写等,这些功能通常在客户端负载均衡中难以实现。
缺点:
- 引入单点故障(SPOF):
如果负载均衡器本身出现故障,则整个服务系统可能会无法正常工作,除非通过高可用配置(如集群)来避免这种情况。 - 增加网络延迟:
请求需要先经过负载均衡器再转发到服务实例,相较于客户端直接访问服务实例,这种方式增加了一次网络跳转和额外的处理时间,可能会增加请求的延迟。 - 额外的基础设施成本:
需要部署和维护额外的负载均衡设备或软件(如硬件负载均衡器、代理服务器等),增加了运维复杂度和成本。 - 不够动态:
服务端负载均衡器通常无法实时感知到服务实例的变化(如新增或下线),特别是在使用硬件负载均衡器时,服务实例的更新和健康检查可能具有一定的滞后性。
对比
客户端负载均衡与服务端负载均衡的对比总结
| 特性 | 客户端负载均衡 | 服务端负载均衡 |
|---|---|---|
| 灵活性 | 高度灵活,可自定义负载均衡策略 | 灵活性较低,但集中化管理更易维护 |
| 复杂性 | 增加客户端复杂性和资源消耗 | 减少客户端复杂性,但增加服务端负担 |
| 管理方式 | 分散管理,每个客户端独立配置 | 集中管理,易于统一配置和监控 |
| 延迟 | 较低(直接访问服务实例) | 较高(需要经过负载均衡器转发) |
| 单点故障 | 无单点故障,依赖服务注册中心 | 负载均衡器本身可能成为单点故障 |
| 基础设施成本 | 低,无需额外硬件或软件支持 | 高,需要负载均衡设备或软件支持 |
| 可扩展性 | 客户端性能决定,扩展性有限 | 高可扩展,适合大规模、高并发场景 |
| 高级功能支持 | 支持有限(需要在客户端实现) | 支持全面(如内容路由、SSL 终止等) |
适用场景
- 客户端负载均衡适用场景:
- 服务实例数量相对较少,且客户端的资源充足。
- 需要更灵活的负载均衡策略和自定义需求。
- 希望减少对集中式负载均衡器的依赖和基础设施成本。
- 需要快速响应服务实例的动态变化。
- 服务端负载均衡适用场景:
- 服务实例数量众多,需要集中管理和高效分发请求。
- 需要实现高级负载均衡功能,如基于内容的路由、SSL 终止、会话保持等。
- 对高可用性和高扩展性要求较高的场景。
- 希望简化客户端的逻辑和减少客户端的资源消耗。
总结
客户端负载均衡和服务端负载均衡各有优缺点,选择哪种方式应根据具体的业务需求、系统架构、性能要求、基础设施成本等因素综合考虑。在许多现代微服务架构中,常常会结合两种方式的优点,使用客户端负载均衡来快速响应服务实例变化,同时在服务端使用负载均衡器来提供高级功能和高可用性保障。
项目有熔断处理吗,什么情况下可以进行熔断
答:有的,用的Hystrix。视情况进行熔断,需保证:核心服务不可熔断,保证该服务高可用
熔断器
熔断器
概念与作用
熔断器(Circuit Breaker)用于防止服务之间的调用失败引发连锁反应。它的作用类似于现实中的保险丝,避免服务不断重试已知失败的请求,从而保护系统的整体可用性和稳定性。
熔断器的主要作用:
- 快速失败:当检测到下游服务存在问题时,熔断器会立即返回错误响应,而不是等待服务超时,从而减少响应时间和系统资源消耗。
- 防止雪崩效应:在微服务架构中,一个服务的故障可能会引起级联故障,影响其他服务的正常运行。熔断器可以在检测到故障时立即中断对该服务的调用,防止故障蔓延。
- 保护系统资源:避免系统资源(如线程、连接等)被无效请求占用,从而确保系统的整体可用性和性能。
- 提高系统的弹性:在某些情况下,熔断器可以帮助系统在部分服务不可用时,继续提供部分或降级的服务。
工作原理
熔断器通常有三种状态:闭合(Closed)、打开(Open)和半开(Half-Open)。
- 闭合(Closed)状态:
在正常情况下,熔断器处于闭合状态,所有请求都正常通过。当请求失败率或响应时间超过设定的阈值时,熔断器状态会从闭合变为打开。 - 打开(Open)状态:
当熔断器进入打开状态后,所有对目标服务的请求都会立即失败,避免对目标服务发起新的请求。熔断器会在打开状态下停留一段时间(即熔断器的“休眠时间”),然后进入半开状态。 - 半开(Half-Open)状态:
熔断器经过一段时间后进入半开状态,此时允许部分请求通过。如果这些请求成功率达到设定的阈值,熔断器会切换回闭合状态,表示服务已恢复;如果请求继续失败,则熔断器重新进入打开状态。
触发条件
- 请求失败率(Failure Rate):
在一段时间内,如果对某个服务的请求失败率超过设定的阈值(例如,超过 50%),则熔断器会触发打开。 - 响应时间(Response Time):
如果请求的响应时间超过设定的阈值(如 2 秒)次数达到一定数量,熔断器也会触发打开。 - 异常数量(Exception Count):
在一定时间窗口内,如果检测到异常(如超时、连接失败等)数量超过阈值,熔断器将触发。
什么情况下可以进行熔断
- 请求失败率过高
- 情况描述: 在一段时间窗口内(例如过去10秒内),对某个服务的请求失败率(如 HTTP 5xx 错误、异常抛出等)超过预设的阈值(例如 50%)。
- 适用场景: 当某个服务持续发生大量请求失败时,很可能是因为服务本身不可用、资源耗尽或出现了严重故障。此时,熔断器应当立即触发,避免继续向该服务发出请求,导致更多的失败或系统负载增大。
- 响应时间过长
- 情况描述: 在一定的时间窗口内,请求的平均响应时间或百分位响应时间(例如 P95)超过预设的阈值(例如 2 秒)。
- 适用场景: 服务响应时间过长可能表示目标服务负载过高、性能瓶颈或发生了网络延迟问题。此时,触发熔断可以避免持续向慢速服务发送请求,导致系统响应速度整体下降。
- 异常数量过多
- 情况描述: 在一个时间窗口内,调用服务时出现的异常次数(如连接超时、请求被拒绝、服务器不可达等)超过设定的阈值(例如连续 5 次异常)。
- 适用场景: 如果短时间内异常数量过多,表明服务可能处于不稳定或不可用状态。此时,触发熔断避免继续进行无意义的请求。
- 请求超时
- 情况描述: 多次请求超时,例如设定的请求超时阈值为 1 秒,而多个请求持续超过此时间。
- 适用场景: 请求超时通常意味着服务响应能力不足或出现了网络故障。通过熔断可以避免系统资源被这些长时间等待的请求消耗掉,保护其他正常请求的性能。
项目实现了流量控制吗,怎么检测流量过大,怎么控制
答:通过Spring Cloud Gateway的令牌桶实现;检测QPS啥的
微服务流量控制的常见方法
微服务流量控制的常见方法
1.基于令牌桶的限流(Token Bucket)
- 原理: 令牌桶是一种常用的限流算法,系统会按照固定速率向令牌桶中放入令牌,请求在到达时需要从桶中获取令牌才能被处理,如果桶中没有令牌,请求会被拒绝或排队等待。通过控制令牌的生成速度和桶的大小,系统能够有效地控制单位时间内处理的请求数量。
- 适用场景: 适用于对突发流量有一定容忍度的系统,可以允许一部分突发流量,但希望在长时间内平滑流量。
- 优点: 可以处理短期突发流量,同时保证长期的请求速率限制。
- 实现示例: 在 Spring Cloud Gateway 中,可以使用
Bucket4j等库来实现令牌桶限流。
2.基于漏桶的限流(Leaky Bucket)
- 原理: 漏桶算法将请求放入一个“桶”中,桶以恒定的速率漏水(即处理请求)。如果桶满了,多余的请求会被丢弃。漏桶算法的核心特点是严格控制请求的处理速率,不允许任何形式的突发流量。
- 适用场景: 适用于对流量的稳定性要求极高的场景,比如对下游服务敏感的外部接口请求。
- 优点: 可以严格控制请求速率,防止系统负载过高。
- 实现示例: 类似于令牌桶算法的实现,也可以用工具库如 Guava RateLimiter 或 Redis 来实现。
3.固定窗口限流(Fixed Window)
- 原理: 将时间划分为一个个固定的时间窗口(例如每秒、每分钟),在每个时间窗口内只允许固定数量的请求。如果在一个窗口内请求数超过了限制值,后续的请求将被拒绝。
- 适用场景: 简单限流场景,适合那些在短时间窗口内流量较为稳定的场景。
- 优点: 实现简单,适合用于系统负载较低且流量稳定的情况。
- 缺点: 容易发生“突发流量”问题,比如两个时间窗口交界时流量突增。
4.滑动窗口限流(Sliding Window)
- 原理: 滑动窗口算法改进了固定窗口的不足,通过一个滑动时间窗口动态统计一定时间范围内的请求数,保证在任意时刻的请求速率不会超过设定值。
- 适用场景: 需要对请求进行更精细化控制的场景,适用于流量波动较大但仍需控制的场景。
- 优点: 相较于固定窗口限流,更能平滑控制请求,避免“突发流量”问题。
如何检测流量过大
如何检测流量过大
1.请求速率(Request Rate)
- 指标描述: 监控每秒(QPS, Queries Per Second)或每分钟的请求数量,判断当前流量是否超过设定的阈值。
- 检测方法: 可以在应用程序级别、网关层或负载均衡器上记录每秒或每分钟的请求数量。可以使用日志分析、AOP拦截、监控工具(如 Prometheus、Datadog)来实现。
2.响应时间(Response Time)
- 指标描述: 监控服务的平均响应时间或百分位响应时间(如 P95、P99 响应时间)。如果响应时间突然变长,可能是流量过大导致的。
- 检测方法: 应用程序级别记录响应时间,或者使用性能监控工具(如 ELK Stack、Grafana)来监控响应时间变化。
3.错误率(Error Rate)
- 指标描述: 监控服务在一段时间内的错误率(如 HTTP 5xx 错误的比例)或异常数量。高错误率可能是由于流量激增导致服务压力过大。
- 检测方法: 在应用中捕获异常、错误日志分析,或使用 APM 工具(如 New Relic、Dynatrace)进行错误率监控。
4.系统资源使用率(System Resource Utilization)
- 指标描述: 监控系统的 CPU、内存、线程池、数据库连接池等资源的使用率。当这些资源使用率持续接近上限时,可能表示流量过大。
- 检测方法: 使用监控工具(如 Prometheus、Zabbix、Grafana)来监控系统资源使用情况。
如何控制流量过大
如何控制流量过大
- 设定合理的流量阈值: 根据历史流量数据、系统容量和服务特性,合理设定流量控制的阈值,避免频繁误触发或限流过于宽松。
- 实时监控和报警: 配置监控系统和报警规则,实时监控流量和服务状态,在流量异常时快速响应。
- 分级流量控制: 根据不同的流量来源、用户或请求类型,设定不同的限流和熔断策略,以达到更精细化的控制。
- 渐进限流策略: 在流量逐渐增大时,逐步收紧限流策略,避免突然切断所有流量。
- 结合多种流量控制措施: 限流、熔断、重试、优先级控制等措施应相互配合,形成一个完整的流量控制策略,以应对不同的流量异常情况。
Mysql中事务的原子性怎么实现
答:整个事务是不可分割的最小单位,事务中任何一个语句执行失败,所有已经执行成功的语句也要会滚,整个数据库状态要恢复到执行事务前到状态。(解释了一遍,但是不知道具体实现)
事务的特性(ACID)
事务的特性(ACID)
原子性(Atomicity):
- 事务是数据库操作的最小单位,事务中的操作要么全部完成,要么全部不完成,不会有中间状态。
- 如果事务在执行过程中发生错误,所有已经执行的操作将被撤销(回滚,rollback),数据库返回到事务开始之前的状态。
一致性(Consistency):
- 事务的执行必须使数据库从一个一致状态转变到另一个一致状态。
- 在事务开始之前和事务结束以后,数据库的完整性约束(如主键约束、外键约束、唯一约束等)没有被破坏。
隔离性(Isolation):
- 在事务执行期间,不允许其他事务访问正在执行的事务中间状态的数据。一个事务所做的修改在最终提交之前,对其他事务是不可见的。
- 隔离性可以通过设置事务隔离级别来实现,MySQL 支持四种隔离级别:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)、可串行化(Serializable)。
持久性(Durability):
- 一旦事务提交,其结果就会永久保存在数据库中,即使系统崩溃也不会丢失数据。
- 数据持久化通常通过写入日志(如 MySQL 的 redo log)来实现。
原子性怎么实现
关键机制
1.日志机制(Undo Log)
MySQL 的存储引擎(如 InnoDB)使用 Undo Log(回滚日志) 来实现原子性。Undo Log 记录了每次事务执行的反向操作,以便在事务失败或被回滚时,能够撤销已经执行的更改。
- 工作原理:
- 当事务开始时,MySQL 将每个操作的旧值记录到
Undo Log中。 - 如果事务提交之前发生了故障,系统可以使用
Undo Log中的信息将数据库回滚到原始状态。 - 当事务成功提交时,
Undo Log将不再需要,最终会被删除。
- 当事务开始时,MySQL 将每个操作的旧值记录到
- 示例:
- 如果在事务中执行了一个更新操作,例如:
UPDATE accounts SET balance = balance - 100 WHERE account_id = 'A';,MySQL 会在执行该操作之前,将账户A的原始balance值写入Undo Log。 - 如果此事务在执行期间失败,MySQL 会根据
Undo Log中的记录,将balance的值恢复到原始状态,实现原子性。
- 如果在事务中执行了一个更新操作,例如:
2.两阶段提交(Two-Phase Commit)
InnoDB 使用 两阶段提交(Two-Phase Commit) 来保证事务的原子性和持久性,特别是在崩溃恢复时。
- 第一阶段:准备阶段(Prepare Phase)
- 当事务准备提交时,InnoDB 会先将所有的修改记录写入 重做日志(Redo Log) 并刷新到磁盘,但此时这些修改并没有真正应用到数据库数据文件中,只是记录在日志中,并将事务状态设置为 “准备提交”。
- 第二阶段:提交阶段(Commit Phase)
- 如果第一阶段成功,InnoDB 会将事务状态更改为“已提交”,然后将日志和数据刷入磁盘,完成提交。
- 如果在第一阶段和第二阶段之间发生故障(如系统崩溃),则系统在恢复时可以使用
Redo Log重新应用所有事务操作,或使用Undo Log进行回滚。
3.崩溃恢复机制
当数据库崩溃或发生异常时,MySQL 使用 Undo Log 和 Redo Log 的组合来确保事务的原子性。
- Undo Log 用于撤销未提交事务的操作。
- Redo Log 用于重做已提交事务的操作。
MySQL 会在崩溃后启动恢复过程,根据 Undo Log 和 Redo Log 的内容,恢复到事务开始之前的一致状态。
实现过程
- 事务开始:MySQL 开始事务操作,记录必要的日志信息。
- 执行操作:在每次数据库修改操作之前,将原始值记录在
Undo Log中。 - 提交事务:
- 两阶段提交:第一阶段将修改记录写入
Redo Log并刷新到磁盘;第二阶段将事务状态设置为“已提交”并应用修改。
- 两阶段提交:第一阶段将修改记录写入
- 崩溃恢复:
- 发生崩溃时,根据
Undo Log回滚未提交的事务,并根据Redo Log重做已提交的事务,确保数据的一致性和完整性。
- 发生崩溃时,根据
知道Sql优化吗,怎么进行调优
答:通过慢查询、skywalk。当发现某一接口调用时间过长时,可以通过skywalking查看该接口的调用情况,确定其是在service层还是mysql查询上时间过长,若是mysql的问题,可以通过explain查看该sql语句的执行计划,看其是否未用索引或者索引失效,再根据具体情况进行sql调优
Sql优化
1.查询分析
1.1 使用 EXPLAIN 分析查询计划
- 使用
EXPLAIN关键字查看 SQL 查询的执行计划,理解查询是如何执行的。 - 通过分析执行计划中的
type、key、rows等字段,识别查询瓶颈和优化点。
1.2 查看慢查询日志
- 启用 MySQL 的慢查询日志,记录执行时间超过阈值的查询。
- 分析慢查询日志找出慢查询并优化。
2.优化 SQL 语句
2.1 选择合适的索引
- 确保查询中的
WHERE子句、JOIN子句、ORDER BY和GROUP BY中使用了合适的索引。 - 避免过多或冗余的索引,因为这会影响写操作性能。
2.2 避免全表扫描
- 尽量避免没有索引的全表扫描,尤其是在大表中。
- 确保索引能够有效地支持查询条件。
2.3 简化查询
- 使用简洁的 SQL 语句,避免不必要的复杂子查询和嵌套查询。
- 尽量将复杂查询拆分为多个简单查询或使用临时表。
2.4 使用适当的表连接
- 优化
JOIN操作,使用合适的连接类型(如内连接、左连接)并确保连接字段有索引。 - 避免使用不必要的表连接,减少连接的表数量。
3.索引优化
3.1 创建和维护索引
- 确保创建索引的字段是查询中经常使用的字段。
- 定期检查和优化索引,删除不再需要的索引。
3.2 避免过度索引
- 避免在每个字段上创建索引,因为这会增加写操作的成本。
- 优化复合索引的顺序,以适应查询的最常用条件。
4.表结构优化
4.1 合理选择数据类型
- 选择合适的字段数据类型,避免使用过大的数据类型。
- 使用
VARCHAR替代CHAR,避免不必要的空间浪费。
4.2 分表和分区
- 对大表进行水平或垂直分表,分散数据存储,提高查询性能。
- 使用表分区(Partitioning)将大表分成多个小表,提升查询性能和管理效率。
5.查询缓存和优化
5.1 使用查询缓存
- MySQL 支持查询缓存,但在高并发场景下查询缓存可能会成为性能瓶颈。
- 根据实际应用场景决定是否启用查询缓存。
5.2 避免不必要的查询
- 避免重复查询相同数据,使用缓存技术(如 Memcached、Redis)减少数据库查询频率。
6.数据库配置优化
6.1 调整数据库参数
- 根据应用需求调整 MySQL 配置参数(如缓存大小、线程数、连接数等)。
- 使用 MySQL 官方的
mysqltuner工具检查数据库性能建议。
6.2 优化事务和锁
- 避免长时间持有锁,减少事务的持续时间。
- 使用合适的事务隔离级别,平衡数据一致性和并发性能。
Redis的数据结构有哪些,Zset底层怎么实现的
答:String、Map、List、Set、ZSet、Bitmap、HyperLogLog、地理位置的;底层没看,不会
Redis数据结构
1.字符串(String):
- 存储简单的文本或二进制数据。
- 常用操作:
SET、GET、INCR。 - 实现:底层使用 动态字符串(SDS, Simple Dynamic String) 来表示字符串。SDS 是一个包含实际字符串内容的内存块,和一个记录字符串长度及容量的元数据。
- 支持动态扩展。
- 提供 O(1) 时间复杂度的字符串操作。
- 内存管理更高效,减少了内存碎片。
2.哈希(Hash):
- 存储键值对集合,类似于字典。
- 常用操作:
HSET、HGET、HGETALL。 - 实现:内部使用哈希表(hash table)。小哈希表使用压缩列表(ziplist),大哈希表使用哈希表结构,以提高查找效率。
- 小哈希表:使用 压缩列表(Ziplist),这是一个高效的内存结构,用于存储小规模的哈希表。
- 压缩列表将哈希表的键值对存储在一个紧凑的内存区域内,适合存储少量元素。
- 大哈希表:使用 哈希表(Hash Table)。
- 哈希表通过链式哈希存储键值对,提供快速的插入和查找操作。
- 小哈希表:使用 压缩列表(Ziplist),这是一个高效的内存结构,用于存储小规模的哈希表。
3.列表(List):
- 存储有序的字符串集合,支持双端操作。
- 常用操作:
LPUSH、RPUSH、LPOP、RPOP。 - 实现:使用双向链表(linked list)和压缩列表(ziplist)。链表适合插入和删除操作,压缩列表用于存储小数据量的列表。
- 小列表:使用 压缩列表(Ziplist),适用于存储小量的列表数据。
- 大列表:使用 双向链表(Linked List),每个节点有指向前后节点的指针。
- 双向链表允许高效的插入和删除操作,但内存消耗较大。
4.集合(Set):
- 存储唯一的无序字符串集合。
- 常用操作:
SADD、SREM、SMEMBERS。 - 实现:内部使用哈希表存储唯一元素。小集合使用压缩列表,大集合使用哈希表。
- 小集合:使用 压缩列表(Ziplist)。
- 大集合:使用 哈希表(Hash Table)。
- 哈希表保证了集合的唯一性和高效的成员查找操作。
5.有序集合(Sorted Set):
- 存储唯一的字符串集合,每个元素有一个分数,自动排序。
- 常用操作:
ZADD、ZRANGE、ZREM。 - 实现:使用跳表(skip list)和哈希表的组合。跳表用于高效的元素排序,哈希表用于快速查找。
- 跳表(Skip List):用于维护有序集合的排序。
- 跳表是一种基于多层链表的概率型数据结构,支持高效的插入、删除和查找操作。
- 哈希表(Hash Table):用于快速查找有序集合中的元素。
- 跳表(Skip List):用于维护有序集合的排序。
6.位图(Bitmap):
- 用于高效地存储和操作位数据。
- 常用操作:
SETBIT、GETBIT。 - 实现:使用位数组,底层是二进制位操作,对内存的操作很高效。
- 位数组是一个紧凑的内存结构,每个位可以表示布尔值,支持高效的位操作。
- 操作位图涉及直接的位操作,如设置、获取和计数。
7.HyperLogLog:
- 用于高效地估算唯一元素的数量。
- 常用操作:
PFADD、PFCOUNT。 - 实现:使用概率算法来估算唯一元素数量。底层基于 HyperLogLog 算法,用小空间估算大数据集合的基数。
- 通过将元素映射到多个哈希桶中,使用概率算法估算数据的基数。
- 需要很少的内存,适合处理大规模数据的基数估计。
8.地理位置(Geospatial):
- 存储和操作地理位置数据。
- 常用操作:
GEOADD、GEOPOS。 - 实现:使用有序集合(sorted set)和 Geohash 算法。通过将地理位置编码为哈希值来进行空间查询。
- Geohash 是一种将地理坐标编码为字符串的算法,使得地理位置可以按位置相近性进行排序。
- 使用有序集合来存储这些编码,从而支持范围查询和地理位置检索。
了解过JVM吗,说一下JVM的内存结构
JVM的内存结构
答:简单把那五个扯了一下,下面的更详细
JVM的内存结构
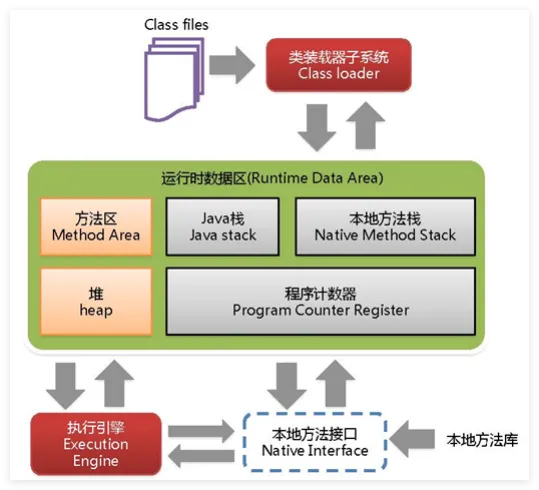
1. 方法区(Method Area)
- 描述:存储类结构信息、常量、静态变量、即时编译器编译后的代码等。
- 作用:
- 线程共享,保存每个类的结构信息,如类名、访问修饰符、字段描述、方法描述等。
- 包含运行时常量池(Runtime Constant Pool),用于存储编译期生成的常量和运行时动态生成的常量。
2. 堆(Heap)
- 描述:所有对象实例和数组的存储区域,堆是 Java 程序中内存的主要部分。
- 特点:
- 线程共享,堆内存是 JVM 中最大的一块内存区域,由垃圾回收器(GC)进行管理。
- 堆分为 新生代(Young Generation) 和 老年代(Old Generation)
- 新生代:存储新创建的对象,进一步划分为 Eden 区和两个 Survivor 区。
- 老年代:存储生命周期较长的对象,经过多次垃圾回收仍然存活的对象会从新生代晋升到老年代。
3. 栈(Stack)
- 描述:每个线程独有的内存区域,存储局部变量表、操作数栈、方法出口等信息。
- 作用:
- 当线程调用一个方法时,JVM 在栈中创建一个对应的栈帧(Stack Frame)。
- 栈帧用于存储该方法的局部变量、操作数、动态链接和方法返回地址。
- 栈内存是线程私有的,每个线程有自己独立的栈。
4. 程序计数器(Program Counter Register)
- 描述:每个线程独有的较小的内存区域。
- 作用:
- 存储当前线程所执行的字节码指令的地址(行号指示器)。
- 用于线程切换时恢复正确的执行位置。
5. 本地方法栈(Native Method Stack)
- 描述:用于执行本地方法(Native Methods)的内存区域。
- 作用:
- 线程私有,类似于 Java 栈,但用于处理由 JVM 执行的本地方法。
- 存储本地方法的调用信息和局部变量。
栈和堆作用
栈和堆作用
1. 栈(Stack)的作用
- 存储线程执行的上下文信息:每个线程在执行 Java 方法时,都会在栈中创建一个栈帧(Stack Frame)来存储该方法的执行状态。
- 栈帧包含:局部变量表、操作数栈、动态链接和方法返回地址等信息。
- 管理方法调用和执行:
- 每个方法调用时,都会在栈中压入一个新的栈帧;方法执行完毕后,该栈帧会被弹出。
- 栈是遵循 LIFO(Last In, First Out)原则的数据结构,适合快速地管理方法调用的入栈和出栈操作。
- 存储局部变量:
- 存储方法内部的基本数据类型变量(如
int、float等)和对象的引用(注意:引用本身存储在栈中,对象的实际数据存储在堆中)。 - 栈内存是线程私有的,每个线程都有自己的栈,不会发生数据共享问题。
- 存储方法内部的基本数据类型变量(如
2. 堆(Heap)的作用
- 存储对象实例和数组:
- 堆是所有线程共享的内存区域,用于存储所有的对象实例和数组。
- 每当使用
new关键字创建对象时,都会在堆上分配内存。
- 垃圾回收管理:
- 堆是由垃圾回收器(GC)管理的主要区域,GC 会定期扫描堆中的对象,释放不再被引用的对象,回收内存。
- 堆内存被分为新生代(Young Generation)和老年代(Old Generation),用于优化对象生命周期管理和垃圾回收效率。
- 共享数据和跨线程通信:
- 因为堆是所有线程共享的,多个线程可以访问同一个对象或数组,允许线程之间的数据共享和通信。
- 由于是共享区域,需要注意多线程访问时的同步问题,以避免线程安全问题。
栈和堆的对比总结
- 栈:
- 用于方法调用和局部变量存储,线程私有,存取速度快。
- 存储数据的生命周期短,随着方法的调用和结束而分配和释放。
- 堆:
- 用于存储所有对象实例和数组,线程共享,数据的生命周期长。
- 由 GC 管理,负责清理不再使用的对象,优化内存使用。
讲一讲栈异常和堆异常
栈异常和堆异常
1. 栈异常(Stack Exception)
1.1 StackOverflowError(栈溢出错误)
原因:当线程栈(Java 栈)空间不足时发生。常见原因是递归调用没有退出条件或过深的递归层次。
现象:
- JVM 会抛出
java.lang.StackOverflowError。 - 程序死循环,无法正常终止。
- 调用栈深度超出预设限度(
-Xss参数设置的栈大小)。
- JVM 会抛出
示例:
1
2
3
4
5
6
7
8
9
10public class StackOverflowExample {
public void recursiveMethod() {
recursiveMethod(); // 递归调用没有结束条件
}
public static void main(String[] args) {
StackOverflowExample example = new StackOverflowExample();
example.recursiveMethod();
}
}上述代码中,
recursiveMethod方法不断调用自身,没有退出条件,导致栈空间耗尽,最终引发StackOverflowError。解决方法:
- 检查并优化递归调用,确保递归有退出条件。
- 调整方法的调用深度,避免过度的嵌套调用。
- 增加线程栈大小,使用 JVM 参数
-Xss来调整栈的大小(不过这只是缓解措施,不是根本解决办法)。
1.2 OutOfMemoryError: Unable to create new native thread(无法创建新线程的内存不足错误)
- 原因:当 JVM 无法为新线程分配足够的栈内存时发生。
- 现象:
- JVM 抛出
java.lang.OutOfMemoryError: Unable to create new native thread。 - 通常在服务器上运行大量线程的程序中较常见。
- JVM 抛出
- 解决方法:
- 优化程序,减少创建的线程数量,使用线程池来重用线程。
- 增加系统的可用内存,或者调整操作系统的线程资源限制。
2. 堆异常(Heap Exception)
2.1 OutOfMemoryError: Java heap space(堆内存不足错误)
- 原因:堆空间耗尽时发生。常见于:
- 应用程序中创建了过多的对象,且这些对象没有被垃圾回收。
- 大量使用了大对象,如大数组或集合类(
ArrayList、HashMap)等。
- 现象:
- JVM 抛出
java.lang.OutOfMemoryError: Java heap space。 - 程序突然中断或性能急剧下降。
- JVM 抛出
- 解决方法:
- 增加 JVM 堆内存大小,使用 JVM 参数
-Xmx设置最大堆内存(如-Xmx2g设置为 2GB)。 - 优化代码,确保及时释放不再使用的对象,减少内存泄漏。
- 使用内存分析工具(如 VisualVM、JProfiler、MAT)找出内存泄漏或占用过多内存的地方。
- 增加 JVM 堆内存大小,使用 JVM 参数
2.2 OutOfMemoryError: GC overhead limit exceeded(GC 开销超过限制错误)
- 原因:垃圾回收器(GC)在尝试回收内存时,耗费了太多时间却只能回收极少量的内存。
- JVM 默认情况下,如果 GC 花费超过 98% 的时间却只能回收不到 2% 的堆内存,会抛出此错误。
- 现象:
- JVM 抛出
java.lang.OutOfMemoryError: GC overhead limit exceeded。 - 程序的响应变得非常慢,大部分时间都在进行垃圾回收。
- JVM 抛出
- 解决方法:
- 增加堆内存大小,减轻垃圾回收器的负担。
- 优化内存使用,减少对象的创建和存活时间。
- 调整垃圾回收器的参数(如
-XX:+UseG1GC使用 G1 垃圾回收器)。
总结
- 栈异常主要涉及方法调用过深或线程创建过多的情况,通常由编写不当的递归或多线程代码引起。
- 堆异常主要与内存管理有关,包括对象创建过多、内存泄漏或垃圾回收效率低等问题。
知道GC机制吗,垃圾回收过程中什么对象应当被回收
答:讲了讲垃圾回收算法、垃圾回收器;引用计数法(还讲了缺点)和可达性分析
GC 的基本原理
GC 的基本原理
GC 主要负责清除 Java 堆(Heap)中的对象。Java 堆被分为不同的区域(如新生代和老年代),GC 会使用不同的算法来确定哪些对象是“垃圾”,即不再被引用的对象,从而释放它们占用的内存。
堆的划分
堆的划分
新生代(Young Generation):
- 包含所有新创建的对象。因为大多数对象都是短命的,所以新生代主要用于存放生命周期短的对象。
- 新生代进一步分为三个部分:
- Eden 区:新对象首先分配到这里。
- Survivor 区:包含两个区域,Survivor 0 (S0) 和 Survivor 1 (S1),用于在 GC 期间保留仍存活的对象。
老年代(Old Generation):
- 存放生命周期较长的对象。当对象在新生代经历了多次垃圾回收仍然存活时,它们会被移动到老年代。
垃圾回收算法
标记-清除算法(Mark-and-Sweep):
- 原理:GC 首先标记所有存活的对象,然后遍历堆,清除所有未被标记的对象。
- 优点:不需要将存活的对象进行移动,直接清除垃圾对象。
- 缺点:容易产生内存碎片,降低内存分配效率。
复制算法(Copying):
- 原理:将内存分为两部分(通常是新生代的 Eden 和 Survivor 区),每次只使用其中一部分。GC 时,将存活的对象从当前区域复制到另一空闲区域,然后清空当前区域。
- 优点:高效地处理对象分配和垃圾回收,避免内存碎片问题。
- 缺点:需要预留一半的内存空间,导致内存利用率降低。
标记-整理算法(Mark-Compact):
- 原理:首先标记所有存活的对象,然后将存活的对象压缩到内存的一端,最后清理未使用的空间。
- 优点:解决了标记-清除算法的内存碎片问题。
- 缺点:对象移动需要时间,标记和压缩过程较慢。
分代收集算法(Generational Collecting):
- 原理:基于“多数对象存活时间短”的经验,将堆划分为新生代和老年代,分别使用不同的算法进行垃圾回收。
- 新生代使用复制算法,因为对象的存活时间短,回收频率高。
- 老年代使用标记-整理或标记-清除算法,因为对象存活时间长,回收频率低。
- 优点:提高了垃圾回收的效率,减少了内存碎片。
垃圾回收器
垃圾回收器
Serial GC:
- 单线程的垃圾回收器,适合单核 CPU 或内存较小的应用。
- 使用标记-复制算法用于新生代,标记-整理算法用于老年代。
Parallel GC(吞吐量优先 GC):
- 多线程垃圾回收器,适用于多核 CPU,追求高吞吐量(减少垃圾回收的总时间)。
- 使用多线程并行回收新生代(复制算法)和老年代(标记-整理算法)。
CMS GC(Concurrent Mark-Sweep GC):
- 并发标记-清除垃圾回收器,减少垃圾回收的停顿时间,适用于响应时间要求较高的应用。
- CMS GC 在标记阶段是并发的,不会停止应用程序线程,但清除阶段仍有可能造成“Stop-the-World”停顿。
- 使用标记-清除算法,容易产生内存碎片。
G1 GC(Garbage-First GC):
- 面向堆内存较大的多核服务器,提供可预测的暂停时间。
- 将堆划分为多个相等大小的区域(Region),混合使用多种算法(标记-整理、复制等)。
- 优先回收垃圾最多的区域,以降低回收停顿时间。
- 适用于大内存、多核环境,平衡吞吐量和响应时间。
ZGC(Z Garbage Collector):
- 适用于低停顿的垃圾回收需求,设计目标是暂停时间不超过 10 毫秒。
- 支持大堆内存,垃圾回收工作与应用线程并发执行。
- 适用于需要低延迟的应用程序,如金融服务、在线交易系统等。
可回收对象
可回收对象
在 Java 的垃圾回收过程中,应当回收的对象是那些不再被引用或不再可达的对象。具体来说,以下对象会被认为是可以被回收的:
1. 不可达对象(Unreachable Objects)
- 一个对象如果没有任何活跃的引用指向它,那么该对象就是不可达的,即不再被程序使用的对象。
- 如何判断对象是否可达?通常使用可达性分析算法(Reachability Analysis):
- 从一组称为 “GC Roots” 的根对象开始,进行引用链的追踪。
- 如果一个对象没有任何途径从 GC Roots 可达(即与 GC Roots 之间没有引用链相连),那么该对象就被认为是不可达的,可以被垃圾回收。
2. 无用的对象(Unused Objects)
- 任何无法从程序中的活动线程、局部变量、静态字段、常量池等访问到的对象,即没有实际用处的对象。
- 这些对象即使还在内存中存在,但由于没有任何引用指向它们,所以是无用的。
3. 循环引用的对象(Circularly Referenced Objects)
- 即使两个对象相互引用,只要从 GC Roots 无法访问到这些对象,垃圾回收器也会回收它们。这是因为 Java 的垃圾回收器使用可达性分析算法,而不是引用计数算法。
- 例如,两个对象
A和B相互引用(A持有B的引用,B持有A的引用),但只要它们在 GC Roots 之外,不可达,它们就会被回收。
- 例如,两个对象
4. 被标记为可终结的对象(Finalizable Objects)
- 对象在没有被引用后,如果其
finalize()方法被调用并执行完成(或者根本没有重写finalize()方法),该对象就会被视为可回收。 - 注意:
finalize()方法是一种不推荐的回收方式,因其不确定性和性能问题。现代的垃圾回收器不依赖finalize()来管理对象生命周期。
具体的垃圾回收算法和对象回收条件
垃圾回收器会根据不同的算法和条件来判断哪些对象需要被回收。
- 标记-清除算法(Mark-and-Sweep):标记所有从 GC Roots 可达的对象,未被标记的对象将被清除。
- 复制算法(Copying):新生代中的对象会在 Minor GC 时,将存活对象从 Eden 区复制到 Survivor 区,未被复制的对象会被清除。
- 标记-整理算法(Mark-Compact):在老年代中使用,标记所有存活对象,然后压缩所有存活对象到内存的一端,清除其余的内存。
Java多线程有哪些状态,Waiting和timed_waiting区别
答:线程枚举类的六种状态;区别就是一个是计时的,到时自动唤醒,另一个必须手动唤醒
多线程六种状态
多线程六种状态
NEW(新建状态)
- 线程对象被创建后,还没有调用
start()方法启动线程。 - 在此状态下,线程只是一个 Java 对象,还没有被操作系统的线程调度器管理。
RUNNABLE(可运行状态)
- 调用
start()方法后,线程进入可运行状态。 - 在此状态下,线程可能正在运行(获得了 CPU 时间片)或者准备运行(等待操作系统线程调度器分配时间片)。
- 注意:在 Java 中,
RUNNABLE状态包括了操作系统层面的 “Running”(运行中) 和 “Ready”(就绪)的状态。
BLOCKED(阻塞状态)
- 线程因为尝试获取一个对象锁(
synchronized同步块或方法)而被阻塞。 - 当一个线程进入同步方法或同步块时,如果需要的锁已经被其他线程持有,该线程会进入
BLOCKED状态,直到锁被释放。 - 线程在阻塞状态下不会消耗 CPU 资源。
WAITING(等待状态)
- 线程通过调用
Object.wait()、Thread.join()或LockSupport.park()等方法进入等待状态。 - 在这种状态下,线程需要等待其他线程显式地唤醒(
notify()、notifyAll()或unpark())才会恢复运行。 - 线程在等待状态下不会消耗 CPU 资源。
TIMED_WAITING(计时等待状态)
- 线程通过调用
Thread.sleep(long millis)、Object.wait(long timeout)、Thread.join(long millis)或LockSupport.parkNanos()/LockSupport.parkUntil()等方法进入计时等待状态。 - 线程在此状态下会等待指定的时间后自动被唤醒,或者在超时时间到达前被其他线程唤醒。
- 线程在计时等待状态下不会消耗 CPU 资源。
TERMINATED(终止状态)
- 线程执行完毕或因异常退出时进入终止状态。
- 一旦线程进入此状态,它不能被再次启动或恢复。
线程状态的转换关系
线程状态的转换关系
- NEW → RUNNABLE:调用
start()方法。 - RUNNABLE → BLOCKED:线程尝试获取对象锁,但该锁已被其他线程持有。
- BLOCKED → RUNNABLE:线程获得对象锁。
- RUNNABLE → WAITING:线程调用
Object.wait()、Thread.join()或LockSupport.park(),等待其他线程的唤醒。 - WAITING → RUNNABLE:线程被其他线程显式唤醒(
notify()、notifyAll()或unpark())。 - RUNNABLE → TIMED_WAITING:线程调用带超时参数的方法(如
sleep(long millis)或wait(long timeout)),在指定时间内等待。 - TIMED_WAITING → RUNNABLE:超时时间到达或者线程被其他线程唤醒。
- RUNNABLE → TERMINATED:线程运行结束或因未捕获的异常退出。
WAITING和TIMED_WAITING区别
WAITING和TIMED_WAITING区别
等待条件不同:
WAITING:线程等待其他线程显式唤醒,没有时间限制。TIMED_WAITING:线程等待其他线程显式唤醒或者指定的时间超时,有时间限制。
使用场景不同:
WAITING:适用于需要无限期等待某个条件满足(如锁或信号)的场景。TIMED_WAITING:适用于需要等待一段时间后继续执行的场景(如定时任务、限时等待某个事件)。
自动恢复机制:
WAITING:必须通过其他线程显式通知来恢复。TIMED_WAITING:可以通过时间超时自动恢复。
什么场景使用Redis,为什么不用MySQL
答:读请求多,像缓存、计数器,用ZSet实现排行榜,SETNX实现分布式锁等;MySQL读写请求的并发量远低于Redis,一个是磁盘IO,一个是内存,速度不一样
Redis使用场景
Redis使用场景
- 缓存:加速数据读取,减少数据库压力。
- 会话存储:管理用户会话数据,如登录状态。
- 排行榜和计数器:实时更新和排序数据,如游戏排行榜。
- 消息队列:实现异步处理和微服务通信。
- 分布式锁:在分布式系统中控制对共享资源的访问。
- 限流与防抖:控制用户请求频率,防止滥用。
- 地理位置数据:存储和查询位置信息。
Redis又快又好,为什么不直接用Redis替代MySQL
答:Redis基于内存,不会直接落盘(当时忘了Redis的持久化)
追问:Redis没有持久化方面的问题可以替代mysql吗
应该是想问事务、表锁行锁啥的,当时没答出来
MySQL与Redis事务的差异
MySQL:
- 使用锁机制(行锁、表锁等)和 MVCC(多版本并发控制)来确保事务的隔离性和数据一致性。
- 支持事务隔离级别(如
READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE),用于控制并发事务之间的相互影响。 - 事务操作使用 日志文件(如
redo log和undo log)来确保持久性和原子性;即使系统崩溃,通过日志恢复未完成的事务或回滚已提交的事务。
Redis:
- 使用单线程模型执行事务,保证事务内命令按顺序执行,不会被其他命令打断。
- 事务开始后,所有命令被放入队列中,直到
EXEC执行时,所有命令才一次性执行。执行过程中,不会被其他客户端命令打断。 - Redis 不支持部分事务回滚。如果事务执行过程中出错(如语法错误),所有命令仍会被执行,只是错误的命令不会生效。
招行
微服务为什么要用Kafka
答:Kafka是一种消息队列,消息队列的使用场景主要有:解耦、异步、削峰。(接着就扯一扯具体场景,讲讲好处啥的)
Kafka
Kafka
Kafka 是一个分布式的流处理平台,最常用于构建实时数据管道和流式数据应用。它由 Apache 基金会维护和开源。
核心概念
- 消息系统:Kafka 是一个高吞吐量的分布式消息队列,支持发布和订阅数据流。消息是 Kafka 的基本单位,它通过“主题(Topic)”进行分类管理。
- 分布式架构:Kafka 以分布式集群的方式部署,能够水平扩展,适合处理大量数据。
- 数据持久化:Kafka 提供高性能的数据持久化能力,消息数据可以存储在磁盘上,支持消息的长期存储和回放。
- 实时流处理:Kafka 不仅能传输数据,还支持实时流处理,可以处理数据流中的大量数据并在几毫秒内响应。
消息队列的好处
消息队列的好处
解耦:将发送方和接收方解耦,发送方只需将消息放入队列,而不需要关心接收方是否在线或如何处理,降低了系统组件之间的耦合度。
异步处理:允许任务异步处理,提高系统的响应速度。发送方可以立即返回而不必等待接收方处理完成,适用于延迟不敏感的任务。
削峰填谷:在流量高峰时,消息队列可以作为缓冲层,将请求排队处理,防止系统被突发流量压垮,平衡系统负载。
提高可用性:通过消息持久化和重试机制,确保消息不会丢失,即使接收方临时不可用或处理失败,系统仍可保持较高的可靠性。
扩展性:支持多消费者模式,多个消费者可以从同一消息队列中读取消息,易于水平扩展,提高系统的处理能力。
Java和C语言,一个面向对象,一个面向编程,两者有什么区别吗
答:用一个例子,把大象装进冰箱用C和Java该怎么实现。
- C语言的话,首先打开冰箱,再把大象塞进去,最后关上冰箱,一共三步;
- 换成Java来做的话,首先会有一个冰箱类,冰箱类里实现打开冰箱、塞入、关闭冰箱方法,再有一个大象类,里面可能有大象的一些属性方法,类似吃东西方法等,实现流程就是,先冰箱和大象new出来,再调用冰箱的打开、塞入方法把大象塞进去,最后调用冰箱的关闭方法。
看似Java为了这个流程做了很多操作,但是如果换一个物体的话,比如把苹果塞进冰箱,C语言就得重新实现该流程,而Java就可以直接创建一个物体抽象类,让大象和苹果都实现该抽象类,冰箱类塞入方法的参数改为该抽象类,即可复用该流程。
Java和C语言的区别
Java和C语言的区别
Java(面向对象编程):
- Java 强调 面向对象编程(OOP),一切都是围绕“对象”和“类”来构建的。
- 主要特性包括 封装、继承、多态 和 抽象。
- 强制使用类和对象,所有功能都必须通过类的实例化来调用(除了静态方法)。
- 通过对象的交互来实现功能模块的解耦和复用,适合复杂、大规模的应用程序开发。
C(过程式编程):
- C 是一种 过程式编程语言,以函数为中心,通过顺序、选择、循环等结构来实现程序的逻辑控制。
- 编写代码时更多地关注具体的执行过程,逐步分解问题,通过函数调用、指针操作来组织和复用代码。
- 更适合底层编程,如操作系统内核、驱动程序和嵌入式系统的开发
面向对象与面向过程的优缺点
面向对象编程(OOP)
优点
- 模块化和封装性:
- OOP 强调将数据和行为封装在对象中,隐藏内部实现细节,暴露统一的接口。这种封装性提高了代码的模块化和可维护性,减少了对外部代码的依赖和影响。
- 复用性和扩展性:
- OOP 支持通过继承和多态来复用和扩展现有的代码。开发者可以创建新的类来继承现有类的功能,或者通过接口实现多态,从而减少重复代码和开发时间。
- 易于维护和修改:
- 面向对象编程的代码通常更容易理解和维护,因为代码是围绕对象和其行为组织的,逻辑更加直观。修改一个对象的行为通常不会影响到其他部分,降低了维护的复杂度。
- 灵活性和可扩展性:
- OOP 提供了更好的灵活性,允许在不改变现有代码的情况下扩展新的功能。例如,通过多态机制,可以在运行时动态改变对象的行为。
- 提高软件质量和稳定性:
- OOP 通过类和对象的设计,提高了软件的质量和稳定性。由于封装和模块化特性,减少了代码间的耦合,降低了出现错误的概率。
缺点
- 性能开销较大:
- OOP 的设计理念需要较多的内存和处理资源,例如对象的创建和销毁、方法调用的开销等,这些都可能导致性能开销较大。对于对性能要求极高的应用场景,OOP 可能不够高效。
- 学习曲线较陡:
- OOP 的概念(如类、对象、继承、多态、封装)可能对初学者来说难以理解,学习和掌握 OOP 需要更多的时间和经验。
- 复杂性较高:
- 面向对象编程适用于复杂系统的设计,但也容易使程序结构变得复杂,尤其是在滥用继承或设计不合理的情况下,会导致代码难以维护和扩展。
- 不适用于所有场景:
- OOP 对于一些简单的、一次性的小程序或脚本来说可能显得过于复杂,过程式编程在这种情况下可能更加简单和直接。
面向过程编程(POP)
优点
- 简单易懂:
- 面向过程编程基于线性逻辑,代码从上到下顺序执行,逻辑简单、清晰,容易理解和实现,适合编写简单的程序。
- 执行效率高:
- 面向过程编程通常比 OOP 执行效率更高,因为它更加接近底层硬件,少了很多对象的封装和方法调用的开销。对于需要高性能的系统级编程(如操作系统、驱动程序),POP 更加高效。
- 控制力强:
- 面向过程编程允许直接操作内存和硬件,提供了更细粒度的控制,适合系统编程、嵌入式开发等对硬件控制要求高的场景。
- 适合小规模程序:
- 过程式编程非常适合小规模、简单的程序或脚本,这些程序的逻辑通常相对简单,不需要复杂的对象模型和设计模式。
缺点
- 缺乏模块化和封装性:
- 面向过程编程主要依赖函数来组织代码,函数之间共享全局数据,容易导致数据的不安全性和代码的高耦合性,使得模块化和封装性较差。
- 代码复用性差:
- 面向过程编程的代码复用性相对较差。函数和数据的结合不紧密,往往需要重复代码来实现类似的功能,难以通过继承和多态来扩展和复用。
- 难以维护和扩展:
- 由于过程式编程缺乏封装和模块化机制,代码通常是相互依赖的,改动一个地方可能会影响多个部分,使得代码的维护和扩展变得困难。
- 不适合复杂系统的开发:
- 面向过程编程难以很好地处理复杂的大型系统。随着系统规模的增大,代码的复杂性和维护成本也会迅速上升。
总结
面向对象编程(OOP) 适合构建复杂、大型、可扩展的系统,提供了更好的模块化、复用性和维护性,但可能带来性能开销和复杂性。
面向过程编程(POP) 适合构建简单、性能要求高的小型程序,具有执行效率高、简单易懂的优点,但缺乏良好的模块化和复用机制,不适合复杂系统的开发。
了解过内存泄漏吗,造成内存泄漏的原因是什么
答:简单来说就是,大内存的对象占着空间又没用上,一直占着不放,我着重讲了ThreadLocal里面弱引用key导致的内存泄漏
Java 中的内存泄漏概念
Java 中的内存泄漏概念
在 Java 中,内存泄漏并不像在 C 或 C++ 这样的手动内存管理语言中那样常见,因为 Java 依靠 垃圾回收器(Garbage Collector,GC) 来自动管理内存。Java 垃圾回收器会定期检查和清理不再使用的对象。但即便如此,Java 程序中仍可能发生内存泄漏,当某些对象不再使用,却由于代码逻辑或设计问题,仍然被其他对象持有引用,导致这些不再需要的对象无法被垃圾回收器回收。
内存泄漏的常见原因
内存泄漏的常见原因
长生命周期对象持有短生命周期对象的引用: 当一个对象的生命周期很长(如全局对象或静态变量)时,它持有一个短生命周期对象的引用,而这个短生命周期对象实际上已经不再需要了,这种情况就会导致内存泄漏。由于长生命周期对象没有被回收,其引用的短生命周期对象也无法被回收。
集合类使用不当: Java 中的集合类(如 List、Map、Set 等)经常用于存储对象,但如果没有及时清理不再使用的对象(如删除元素或清空集合),这些对象仍然会被引用并保留在内存中,导致内存泄漏。例如,在 HashMap 中,如果忘记清理那些已经不再需要的键或值,内存就不会被释放。
静态集合类: 静态变量的生命周期与整个应用程序的生命周期相同。如果静态集合类(如 static List、static Map 等)中存储了大量对象,且这些对象不再需要时没有被及时移除,就会导致内存泄漏。
监听器和回调的注册和未注销: 事件监听器(如 GUI 应用中的 ActionListener)或回调方法(如异步调用的回调)如果注册后未能及时注销,会使这些监听器或回调对象无法被垃圾回收,从而引起内存泄漏。
内部类和外部类的引用: 非静态内部类会持有对其外部类的引用,如果外部类对象已经不再使用,但其内部类对象依然被持有引用(例如在某些线程或异步回调中),就会导致外部类对象无法被垃圾回收。
ThreadLocal 使用不当: ThreadLocal 用于在多线程环境下为每个线程提供独立的变量副本,但如果在使用完 ThreadLocal 后没有调用 remove() 方法来清除值,就可能导致内存泄漏,特别是在使用线程池时,因为线程池中的线程可能不会终止,而是被重复使用。
ThreadLocal弱引用key导致的内存泄漏
ThreadLocal弱引用key导致的内存泄漏
1. ThreadLocal 的内部实现机制
ThreadLocal 的实现依赖于每个线程都有一个 ThreadLocalMap,ThreadLocalMap 是 ThreadLocal 类的一个内部类。每个线程在其内部维护了一个这样的 ThreadLocalMap,用于存储 ThreadLocal 变量。
ThreadLocalMap 中的每个条目是一个键值对,键是 ThreadLocal 实例本身,而值是线程本地的值。为了防止 ThreadLocal 实例本身不被使用后仍占用内存,ThreadLocalMap 使用了 弱引用(WeakReference) 来存储这些键。
2. 弱引用(WeakReference)和内存泄漏的原因
- 弱引用(WeakReference):在 Java 中,弱引用是指被
WeakReference包装的对象,当垃圾回收器(GC)运行时,如果一个对象只被弱引用指向,那么该对象将被回收。使用弱引用的目的是允许对象被垃圾回收,以避免占用内存。 - 在
ThreadLocalMap中,键(ThreadLocal对象)是用弱引用来存储的,因此,如果某个ThreadLocal实例没有外部强引用指向它,那么该实例就会被垃圾回收。但是,ThreadLocalMap中的值(即线程局部变量的值)是用强引用存储的。
内存泄漏的发生过程
- 当一个
ThreadLocal实例不再被外部引用时,该实例的弱引用键会在下一次 GC 时被回收。 - 然而,
ThreadLocalMap中的值(强引用)没有被回收,仍然存在于ThreadLocalMap中。 - 由于
ThreadLocal的键已经被回收,因此这些值变成了 孤儿对象,无法通过任何引用路径被访问到。除非手动清理这些孤儿对象,它们会一直存在,造成内存泄漏。
3. 如何避免 ThreadLocal 中的内存泄漏
正确地清理 ThreadLocal 值:使用完 ThreadLocal 变量后,务必调用 remove() 方法来清理数据。ThreadLocal 类提供了一个 remove() 方法,可以清除当前线程中的局部变量的值,避免内存泄漏。例如:
1 | ThreadLocal<MyObject> threadLocal = new ThreadLocal<>(); |
避免使用不必要的 ThreadLocal 变量:只在需要时使用 ThreadLocal,并尽量缩小其作用范围。不要将 ThreadLocal 对象存储在静态变量或全局对象中,因为这会增加内存泄漏的风险。
定期检查和清理长时间运行的线程:对于长时间运行的线程(例如线程池中的线程),定期检查其 ThreadLocalMap 并清理无用的条目。
项目中异常是怎么处理的
答:定义了全局的异常类,用枚举类规范好各种业务场景的报错信息。在对可能出现异常的业务场景,比如JSON转对象的时候,为了避免数据结构映射错误,应在转化时手动捕获该异常,增加代码健壮性。
Error和Exception有什么区别
Error和Exception有什么区别
Error
- 定义:
Error表示严重的错误,是程序无法控制的错误状况。它们通常是由 JVM(Java Virtual Machine)引发的,表示系统级问题,通常程序无法处理或恢复这些问题。 - 用途:
Error通常用于表示 虚拟机运行错误 或者 资源不足 等不可恢复的情况。例如,OutOfMemoryError表示内存耗尽,StackOverflowError表示堆栈溢出,这些错误发生时,程序通常无法再继续执行。 - 处理方式:一般来说,
Error不应该被捕获(catch),也不应该被程序处理,因为它们表示的是程序之外的问题,例如硬件故障、系统崩溃、JVM 内部错误等。Error通常会导致程序非正常终止。 - 常见的
Error示例:OutOfMemoryError:内存不足。StackOverflowError:栈内存溢出,通常是由于递归调用过深。VirtualMachineError:JVM 遇到的严重错误,如InternalError、UnknownError等。NoClassDefFoundError:类定义没有找到,通常是由于类文件在运行时丢失或不可用。
Exception
- 定义:
Exception表示程序中出现的 异常情况 或 错误条件。这些异常可能是由于程序错误、用户输入错误或其他预期的条件引起的。 - 用途:
Exception被设计用来表示 程序级错误,即程序运行过程中可以预料、处理和恢复的异常情况。例如,尝试访问一个不存在的文件或处理错误的用户输入。 - 处理方式:
Exception可以也应该被捕获(catch)并处理。通过使用try-catch块,程序可以捕获这些异常并进行适当的处理,以便程序能够继续执行或优雅地退出。 - 常见的
Exception示例:NullPointerException:尝试访问一个空对象引用。ArrayIndexOutOfBoundsException:数组访问越界。IOException:I/O 操作失败或中断。FileNotFoundException:试图访问的文件不存在。SQLException:数据库操作中发生错误。
总结
Error:代表系统级错误或严重的问题,通常不可恢复。程序不应尝试捕获和处理它们。
Exception:代表程序级异常,可预期、可处理,分为受检异常(必须显式处理)和非受检异常(不强制处理)。
受检异常(编译时异常)和 非受检异常(运行时异常)
受检异常(编译时异常)和 非受检异常(运行时异常)
受检异常(编译时异常)
- 定义:受检异常是指那些在编译时被强制检查的异常,这意味着编写代码时必须要用
try-catch块处理它们,或者在方法签名中用throws关键字声明。 - 用途:通常用于表示一些外部条件(如文件不存在、网络连接失败、数据库访问错误等)导致的错误。这些错误是程序无法预测但可以合理处理的。
- 常见的受检异常:
IOException:文件操作、网络操作等 I/O 操作中产生的异常。SQLException:与数据库操作相关的异常。ClassNotFoundException:类加载时找不到指定类。
非受检异常(运行时异常)
- 定义:非受检异常是指在编译时不强制检查的异常,通常是程序逻辑错误导致的异常。这类异常继承自
RuntimeException类。 - 用途:这些异常表示编程错误,比如访问空对象引用(
NullPointerException)、数组越界(ArrayIndexOutOfBoundsException)、数字格式错误(NumberFormatException)等。通常,不需要强制捕获这些异常,因为它们通常表示程序中的漏洞或逻辑错误。 - 常见的非受检异常:
NullPointerException:访问或修改空对象引用。ArithmeticException:算术运算中的异常,如除以零。IndexOutOfBoundsException:访问列表或数组时索引越界。IllegalArgumentException:传递给方法的参数不合法。
常见的异常
受检异常(编译时异常)
IOException:I/O 操作失败或中断时引发的异常。所有输入输出操作的父类异常,包括文件操作、网络操作等。
FileNotFoundException:当尝试打开一个不存在的文件时抛出。EOFException:当文件或流到达末尾时抛出。
SQLException:与数据库操作相关的异常,当 JDBC 操作失败时抛出。例如,无法建立数据库连接、查询失败等。
ClassNotFoundException:当 Java 应用程序试图通过名称加载某个类,而这个类不存在时抛出。
CloneNotSupportedException:当对象不实现 Cloneable 接口而调用 clone() 方法时抛出。
InterruptedException:当一个线程在等待、睡眠或执行一些阻塞操作时,被其他线程中断而抛出。
NoSuchMethodException:调用一个方法(通过反射)但该方法在目标类中不存在时抛出。
InstantiationException:当应用程序试图通过反射创建某个类的实例,但该类是一个抽象类或接口时抛出。
MalformedURLException:当构造一个 URL 对象但 URL 格式无效时抛出。
ParseException:格式不正确时抛出,例如日期字符串格式错误
非受检异常(运行时异常)
NullPointerException:试图在空对象引用上调用方法或访问字段时抛出。非常常见,表示程序中的一个严重错误。
IndexOutOfBoundsException:访问数组或集合时,索引超出范围时抛出。
ArrayIndexOutOfBoundsException:数组索引越界时抛出。StringIndexOutOfBoundsException:字符串索引超出范围时抛出。
ArithmeticException:算术运算时发生错误(如除以零)时抛出。
IllegalArgumentException:传递给方法的参数不符合预期要求(不合法)时抛出。
NumberFormatException:将字符串转换为数字格式失败时抛出(例如,将 “abc” 转换为整数)。
IllegalStateException:对象处于非法状态时抛出,通常表示方法调用的顺序不对或方法调用时对象的状态不符合预期。
ClassCastException:类型转换失败时抛出,例如试图将一个对象强制转换为其不兼容的类型。
UnsupportedOperationException:在不支持的情况下,试图执行某个操作时抛出,通常在集合的不可修改视图中使用。
ConcurrentModificationException:当一个线程正在对集合进行遍历时,另一个线程对该集合进行了结构修改时抛出。
IllegalAccessException:试图访问或修改没有访问权限的类、字段或方法时抛出。
其他常见异常
StackOverflowError:表示程序的调用栈过深(如递归无限调用),导致栈溢出。
OutOfMemoryError:表示 JVM 的堆内存耗尽。
Control,Service层出现异常怎么处理
Control,Service层出现异常怎么处理
Service 层异常处理
Service 层是业务逻辑的核心,它处理数据并与数据库交互。异常处理的关键在于确保异常不会直接影响 Controller 层或造成服务崩溃。
1. 捕获和抛出异常
在 Service 层,通常需要对可能抛出的异常进行捕获,并根据情况抛出自定义异常或转换为适当的异常类型。常见的做法是创建自定义异常类来描述业务相关的异常。
- 自定义异常类: 创建一个或多个自定义异常类来描述应用程序中的业务异常。
- 捕获和转换异常: 在
Service层的方法中,可以捕获低级异常(如SQLException),然后将其转换为自定义的业务异常。
2. 使用 @Transactional 注解
如果 Service 方法涉及到数据库事务,则不可捕获业务异常,需使用 @Transactional 注解来确保事务的一致性
Controller 层异常处理
Controller 层负责处理客户端的请求并返回响应。异常处理的目标是返回友好的错误消息,避免将服务器内部信息暴露给客户端,同时确保服务的稳定性。
1. 使用 @ExceptionHandler 注解
可以在 Controller 中使用 @ExceptionHandler 注解来处理特定类型的异常,并返回自定义的错误响应。
2. 使用全局异常处理器(@ControllerAdvice)
@ControllerAdvice 可以创建一个全局异常处理器来处理应用程序中所有控制器的异常,避免在每个控制器中重复编写异常处理代码。
日志记录
无论是 Service 层还是 Controller 层,日志记录都是异常处理中的重要环节。通过日志系统(如 Log4j、SLF4J 等),可以捕获并记录异常的详细信息,包括异常类型、错误消息、堆栈跟踪等,便于后续排查和修复问题。
返回友好的错误信息
在 Controller 层异常处理时,应该确保返回给客户端的错误信息是友好且安全的。避免直接返回堆栈信息或敏感数据,使用标准的 HTTP 状态码(如 400、404、500 等)和有意义的错误消息来指示问题。
数据库
数据库三范式
数据库三范式
- 第一范式:强调的是列的原子性,即数据库表的每一列都是不可分割的原子数据项。
- 第二范式:要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
- 第三范式:任何非主属性不依赖于其它非主属性。
设计表的时候会不会使用外键
答:通常不会使用物理外键,这会增加数据库性能开销,也加大了数据库迁移的困难;一般使用的是逻辑外键,即增加where条件进行约束
物理外键和逻辑外键的区别
物理外键(Physical Foreign Key)是数据库表中的实际外键约束。在关系型数据库中,物理外键用于强制执行两个表之间的引用完整性。它们通过数据库管理系统(DBMS)的约束机制来确保外键的值总是指向另一个表中的有效主键值。
优点
- 数据完整性保障:物理外键通过数据库本身的机制来强制执行引用完整性,防止无效的数据插入。例如,不能插入一个指向不存在的主键的外键值。
- 自动化维护:数据库可以自动处理外键约束(如级联更新和删除),减少手动维护的工作量和出错的风险。
- 简化查询:使用物理外键可以更方便地进行关联查询,因为数据库管理系统知道表之间的关系,可以自动优化查询。
- 性能优化:在某些数据库管理系统中,物理外键可以帮助优化器更好地理解数据之间的关系,从而优化查询性能。
缺点
- 性能开销:插入、更新或删除涉及外键约束的数据时,数据库需要检查和维护这些约束,这会增加一定的性能开销,尤其是在大量数据操作时。
- 迁移复杂性:当进行数据库迁移或数据模型更改时,物理外键约束可能会增加迁移的复杂性,需要处理外键依赖关系。
- 灵活性较差:物理外键强制执行严格的引用完整性,可能不适用于需要更大灵活性的应用场景(如多租户系统中的数据隔离)。
- 可移植性问题:不同数据库管理系统对外键支持的实现和表现有所不同,在跨数据库平台迁移时可能会带来兼容性问题。
逻辑外键(Logical Foreign Key)是通过应用程序代码或数据库触发器来实现的外键约束。在逻辑外键中,不在数据库层面定义外键约束,而是在应用程序或业务逻辑中确保数据的引用完整性。
优点
- 更高的灵活性:逻辑外键不依赖于数据库约束,因此在需要更灵活的数据处理时更容易调整。例如,可以根据特定业务需求来处理异常情况或特定的引用规则。
- 性能更好:由于没有数据库级别的外键约束,插入、更新和删除操作通常比物理外键快,因为不需要数据库检查外键约束的合法性。
- 更好的可移植性:逻辑外键独立于数据库实现,更易于在不同的数据库管理系统之间迁移数据模型。
- 简化数据库管理:在某些复杂场景下,逻辑外键可以简化数据库的物理设计和管理,因为不需要管理复杂的外键依赖关系。
缺点
- 缺乏数据完整性保障:由于逻辑外键不在数据库层面强制执行,数据完整性完全依赖于应用程序逻辑的正确性。如果应用程序逻辑出错,可能导致数据不一致或无效引用。
- 更高的开发和维护成本:需要在应用程序或触发器中实现引用完整性逻辑,增加了开发复杂度和维护成本。
- 难以进行级联操作:在没有物理外键的情况下,必须手动实现级联更新或删除操作,这可能更复杂且更容易出错。
- 难以调试:如果数据出现不一致或错误情况,难以追踪问题的来源,因为约束是在应用程序层面而不是数据库层面执行的。
总结
- 物理外键 更适合需要严格数据完整性的场景,例如财务系统、银行系统等关键业务系统,在这些场景中,数据的一致性和完整性比性能更重要。
- 逻辑外键 适合需要高性能和灵活性的场景,例如某些大规模数据处理系统或多租户应用系统,在这些场景中,数据完整性可以通过应用层逻辑来保证。
内连接与左右连接的区别
内连接与左右连接的区别
内连接(INNER JOIN)
内连接返回两个表中满足连接条件的记录(即两个表都有匹配的记录,取交集)。只有在两个表的连接列有匹配的情况下,才会返回结果行。
语法:
1
2SELECT * FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;结果:
仅返回
table1和table2中满足ON条件的那些行。如果在table1或table2中某行没有匹配项,那么该行不会出现在结果集中。使用场景:
当你只关心两个表中都有匹配数据的情况时,使用内连接。例如,查找那些在两个表中都有订单记录和对应客户信息的情况。
左连接(LEFT JOIN 或 LEFT OUTER JOIN)
左连接返回左表(table1)中的所有记录,以及右表(table2)中满足连接条件的记录。如果右表中没有匹配的记录,则结果中相应的右表列将包含 NULL。
语法:
1
2SELECT * FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;结果:
返回左表中的所有行。如果右表中有匹配项,则包含匹配的行;如果没有匹配项,右表的列则用
NULL填充。使用场景:
当你希望获得左表中所有记录,即使在右表中没有匹配的记录时,也希望返回左表的所有数据。例如,查找所有客户及其对应的订单,如果有客户没有订单记录,也希望显示客户信息。
右连接差不多,左右表反过来
| 特性 | 内连接(INNER JOIN) | 左连接(LEFT JOIN) |
|---|---|---|
| 返回结果 | 两个表中都有匹配项的记录 | 左表中的所有记录,以及右表中与其匹配的记录 |
| 没有匹配项的处理 | 记录不在结果中显示 | 没有匹配项的右表列显示为 NULL |
| 使用场景 | 当只需要两个表中都存在的数据时 | 需要获取左表中的所有记录,无论是否存在右表的匹配项 |
| 数据量和性能 | 返回的行数可能较少(仅匹配项) | 返回的行数可能更多(包含左表所有记录) |
SQL执行计划
SQL执行计划
在MySQL中,使用 EXPLAIN 关键字来查看执行计划(即SQL语句前加个EXPLAIN)。例如:
1 | EXPLAIN SELECT * FROM customers WHERE id = 1; |
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | orders | ref | idx_customer | idx_customer | 4 | const | 10 | Using where |
| 字段 | 描述 |
|---|---|
| id | 标识查询中各个步骤的顺序,通常用于显示执行计划的层次结构。 |
| select_type | 查询的类型,如 SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)等。 |
| table | 当前操作涉及的表名。 |
| type | 表示访问类型,数据访问方法,如 ALL、INDEX、RANGE、REF、CONST、SYSTEM等。 |
| possible_keys | 查询中可能使用的索引列表。 |
| key | 优化器实际使用的索引名。 |
| key_len | 使用的索引的长度。 |
| ref | 显示索引列的比较方式或匹配情况。 |
| rows | 优化器估计查询操作要扫描的行数,反映了操作的代价。 |
| Extra | 额外信息,描述其他查询操作,如 Using where、Using index、Using temporary、Using filesort等。 |
a. type 字段(访问类型)
ALL:全表扫描。数据库扫描表中的所有行来找到匹配的数据,这是性能最差的访问类型之一。通常表示没有使用索引,建议优化查询或添加合适的索引。INDEX:索引扫描。扫描整个索引,这比全表扫描更快,但仍然需要优化。RANGE:范围扫描。根据范围条件(如BETWEEN或<、>)扫描索引,比全索引扫描更高效。REF:引用扫描。根据索引列查找匹配的行,通常出现在使用非唯一索引或主键连接时,比RANGE更高效。EQ_REF:等值引用扫描。用于唯一索引或主键连接的情况,性能非常高。CONST:常量扫描。数据库在优化阶段就能确定结果集,这种类型的访问是最优的。SYSTEM:系统扫描。表示表只有一行(如系统表),此时成本极低。
优先级从低到高依次为 ALL < INDEX < RANGE < REF < EQ_REF < CONST < SYSTEM。如果执行计划中出现 ALL 或 INDEX,可能需要优化查询语句或添加索引。
b. key 和 possible_keys 字段
possible_keys:显示查询中可能用到的索引。如果为空,表示查询中没有可能使用的索引,需要考虑创建索引。key:实际使用的索引。理想情况下,key应该包含在possible_keys中。
如果 key 为空或 possible_keys 列表为空,表示查询没有使用索引,可以考虑检查索引的创建和使用情况。
c. rows 字段
- 显示数据库优化器估算要读取的行数。行数越大,查询的成本和执行时间越高。
如果 rows 数量过大,可能表示查询效率低。优化策略包括使用更有效的索引、改善查询条件等。
d. Extra 字段
Using where:表示使用了WHERE过滤条件来过滤结果集中的行,通常是正常情况。Using index:表示查询只使用了索引中的列来满足查询要求,没有额外访问表数据。这是一个理想情况。Using temporary:表示查询使用了临时表来存储中间结果,可能会导致性能问题。Using filesort:表示数据库无法通过索引进行排序,而是使用了文件排序(通常是磁盘排序),这可能会严重影响性能。
尽量避免 Using temporary 和 Using filesort,因为它们会增加I/O操作和内存消耗。使用合适的索引可以减少这些操作。
讲讲http里的Cookie和Session
答:可以存储身份信息的数据,cookie是在客户端的,session是在服务端的
Cookie和Session的区别
Cookie
Cookie 是一种小型文本文件,由服务器生成并发送给客户端(通常是浏览器),然后由客户端存储下来。每次客户端发起请求时,都会自动携带这些 Cookie 信息,以便服务器识别客户端。Cookie 通常用于存储会话标识、用户偏好设置、购物车内容等信息。
特点:
- 存储位置:存储在客户端浏览器中,大小限制通常为 4KB 左右。
- 有效期:可以设置过期时间(
Expires或Max-Age),在此之前,浏览器会自动保存并发送 Cookie。如果不设置过期时间,Cookie 是会话 Cookie,会在浏览器关闭时自动删除。 - 作用域:通过
Domain和Path限制 Cookie 的作用域。Domain指定了 Cookie 对应的域名,Path指定了 Cookie 生效的路径。 - 安全性:通过
Secure和HttpOnly标志增加安全性Secure:要求 Cookie 只能通过 HTTPS 发送,保证传输加密。HttpOnly:防止 JavaScript 访问 Cookie,减少 XSS(跨站脚本攻击)风险。
使用场景:
- 会话管理:如用户登录状态的保持。
- 个性化设置:如用户偏好主题、语言选择等。
- 跟踪分析:如用户行为分析、广告投放跟踪等。
Session
Session 是一种服务器端的会话管理机制,用于在多个请求之间保持用户的状态。服务器为每个用户创建一个唯一的会话(通常是一个包含唯一会话 ID 的对象),并将会话 ID 发送给客户端(通常通过 Cookie 传递)。客户端在随后的请求中会携带该会话 ID,使得服务器能够识别用户的状态。
特点:
- 存储位置:Session 数据存储在服务器端,客户端只存储一个会话 ID(通常通过 Cookie)。
- 安全性:比 Cookie 更安全,因为实际的会话数据不在客户端存储,而是保存在服务器上。通过会话 ID 进行关联,可以有效防止客户端篡改。
- 生命周期:Session 的默认有效期通常是服务器配置的时间段(如 30 分钟)。当用户在此时间内不进行任何操作,Session 将过期。可以手动配置或扩展 Session 的生存期。
- 数据量:没有像 Cookie 那样严格的大小限制,因为数据保存在服务器端,但过多的 Session 数据会影响服务器性能和内存消耗。
使用场景:
- 用户认证:保存用户登录信息、权限等。
- 购物车:保存用户在电商网站上的购物车状态。
- 跨页面数据共享:在同一个会话期间的不同页面之间共享数据。
Cookie 和 Session 的区别
| 特性 | Cookie | Session |
|---|---|---|
| 存储位置 | 客户端(浏览器)。 | 服务器端。 |
| 安全性 | 相对较低,数据可以被用户查看和篡改。 | 较高,数据存储在服务器端,用户无法直接访问。 |
| 存储大小 | 通常最多4KB。 | 没有明确的大小限制,但会消耗服务器资源。 |
| 生命周期 | 可设置过期时间,或会话结束后删除。 | 受服务器配置控制,一般在不活动一段时间后过期。 |
| 使用场景 | 保存少量非敏感数据(如用户偏好、跟踪信息)。 | 保存敏感数据(如用户身份、权限、购物车数据)。 |
| 性能影响 | 客户端负责存储和发送,服务器资源消耗小。 | 服务器需要维护和管理每个用户的会话,资源消耗较大。 |
总结
- Cookie 是一种客户端存储机制,适用于存储较小、非敏感数据和长期保存的数据,但存在安全风险。
- Session 是一种服务器端存储机制,适用于存储敏感数据和临时数据,但需要服务器资源支持。
- 两者结合使用可以发挥各自优势,既确保数据安全,又提升用户体验。
如何配合使用
- 身份认证:服务器在用户首次登录时创建一个 Session,并通过 Cookie 将会话 ID 发送给客户端。之后,客户端每次请求都会携带该会话 ID,服务器根据此 ID 查找对应的会话数据,从而保持用户的身份和状态。
- 持久化数据和临时数据:持久化数据(如用户偏好设置)可以存储在 Cookie 中,因为这些数据需要长期保存在客户端。而临时数据(如购物车状态、用户身份)则更适合存储在服务器端的 Session 中。
如果浏览器把cookie禁用了怎么办
答:被ban了就塞到请求体里[doge],在哪传不是传
浏览器把cookie禁用了怎么办
如果浏览器禁用了 Cookie,应用程序将无法依赖 Cookie 来存储和传输用户的状态信息。这会影响基于 Cookie 的会话管理、用户身份验证和个性化设置等功能。因此,我们需要使用其他替代方案来实现这些功能。
应对 Cookie 禁用的替代方案
URL 重写(URL Rewriting)
将会话 ID 或状态信息直接附加在 URL 上作为查询参数。例如:
1
https://example.com/page?session_id=abcdef123456
优点:在 Cookie 被禁用时,仍然可以保持会话状态。
缺点:可能会导致 URL 变长,容易暴露敏感信息,用户复制或分享 URL 时也可能意外泄露会话信息。此外,URL 重写需要在每个链接上手动附加会话信息,开发和维护成本较高。
隐藏表单字段(Hidden Form Fields)
在每个表单中使用隐藏字段传递会话 ID 或状态信息。例如:
1
<input type="hidden" name="session_id" value="abcdef123456">
优点:在用户提交表单时能够传递会话信息,适用于多步表单或提交较多数据的场景。
缺点:只能在用户提交表单的情况下传递会话信息,不适用于通过链接或 AJAX 请求传递状态的场景。
本地存储(Local Storage)或会话存储(Session Storage)
- 使用 HTML5 的
localStorage或sessionStorage在浏览器端存储数据。它们提供了比 Cookie 更大的存储空间,且数据不会自动随请求发送给服务器。 - 优点:在浏览器端存储数据,避免了 Cookie 的大小限制,适合存储大量数据;浏览器禁用了 Cookie 也不影响本地存储的使用。
- 缺点:不能跨域使用;与服务器通信时,需要手动将存储中的数据添加到请求头或请求体中,增加了开发复杂度;
localStorage和sessionStorage在安全性上依然面临 XSS 攻击的风险。
- 使用 HTML5 的
基于 IP 地址和 User-Agent 的会话管理
- 在服务器端记录客户端的 IP 地址和 User-Agent 信息,用于唯一标识用户会话。
- 优点:不依赖 Cookie,用户无法禁用。
- 缺点:IP 地址可能会因用户使用代理或 VPN 而发生变化,导致会话失效;多个用户共享同一个 IP(如公司网络)时,可能会导致混淆。
服务器端 Token 验证
- 在服务器端生成一个唯一的 Token(令牌),并在初始响应中通过 URL、隐藏表单字段或响应头传递给客户端。客户端在后续请求中附加该 Token,以维持会话状态。
- 优点:不依赖 Cookie,可以灵活选择传输方式(URL、表单或请求头)。
- 缺点:与 URL 重写和隐藏表单字段类似,可能面临安全风险(如 URL 泄露),需要使用 HTTPS 确保数据传输安全。
美团
Lombok用过哪些注解
答:@Data 、@Slf4j、@RequiredArgsConstructor。
最后一个可以搭配final实现SrpingBoot的自动注入,可以去看看
项目难点
多线程
线程池构造
答:讲了用 Executors 工具类和七大参数构造的
Executors 工具类
newFixedThreadPool(int nThreads)- 创建一个固定大小的线程池,池中始终保持指定数量的线程。
- 适合执行长期的任务,保证线程数量的稳定。
1
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(4);
newCachedThreadPool()- 创建一个可以根据需要创建新线程的线程池,但在以前构造的线程可用时将重用它们。
- 适合执行大量的短期异步任务。
- 如果线程池大小超过处理需求,则会回收空闲线程;如果任务数量增加,则会增加线程数量。
1
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
newSingleThreadExecutor()- 创建一个单线程化的线程池,即只有一个线程来执行任务,所有任务按照指定顺序(FIFO、LIFO、优先级)执行。
- 适合需要按顺序执行任务的场景。
1
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
newScheduledThreadPool(int corePoolSize)- 创建一个定长线程池,支持定时及周期性任务执行。
- 适合需要定时执行或周期执行任务的场景。
1
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
ThreadPoolExecutor 自定义
1 | ThreadPoolExecutor threadPool = new ThreadPoolExecutor( |
参数解释:
corePoolSize:核心线程数。线程池中始终保持的最小线程数,即使这些线程是空闲的。maximumPoolSize:最大线程数。线程池中允许的最大线程数。keepAliveTime:当线程池中的线程数量超过核心线程数时,多余的空闲线程的存活时间。unit:keepAliveTime的时间单位。workQueue:任务队列,存储等待执行的任务。- 常用的队列类型有:
LinkedBlockingQueue:一个无界队列,任务队列不受限制。ArrayBlockingQueue:一个有界队列,任务数量受到限制。SynchronousQueue:直接交接的队列,不会保存任务,每次提交任务都必须找一个空闲线程来处理。
- 常用的队列类型有:
threadFactory:用于创建新线程的工厂,可以通过自定义线程工厂给线程命名或设置为守护线程等。handler:拒绝策略,当任务队列已满且线程数量已达到最大线程数时的处理策略。- 常用的拒绝策略:
AbortPolicy:默认策略,抛出RejectedExecutionException异常。CallerRunsPolicy:由调用线程(提交任务的线程)执行任务。DiscardPolicy:直接丢弃任务,不做任何处理。DiscardOldestPolicy:丢弃最早的未处理任务,并尝试重新提交新的任务。
- 常用的拒绝策略:
线程工厂一般用来干什么
答:命名、设置优先级
线程工厂
自定义线程名称:
- 通过线程工厂为每个线程指定一个有意义的名称,有助于在调试和监控时更容易区分和跟踪线程。例如,可以根据线程池类型或业务逻辑给线程命名。
设置线程的优先级:
- 可以在创建线程时指定线程的优先级(
Thread.MIN_PRIORITY到Thread.MAX_PRIORITY),以控制线程调度的优先级。默认情况下,线程的优先级是Thread.NORM_PRIORITY。
将线程设置为守护线程:
- 可以将线程设置为 守护线程(Daemon Thread),这意味着当所有非守护线程结束时,JVM 将退出。守护线程通常用于执行后台任务或服务。
定义线程的异常处理策略:
- 可以自定义线程的异常处理器(
UncaughtExceptionHandler),在线程运行过程中遇到未捕获的异常时指定如何处理。
增强线程的安全性和管理性:
- 通过线程工厂,可以统一设置线程的上下文,如安全管理器、上下文类加载器等。这样,可以控制线程的执行环境,增强应用程序的安全性和管理性。
ThreadLocal 的底层原理
ThreadLocal 的底层原理
ThreadLocal 的核心机制在于它通过每个线程对象(Thread)中的一个专属数据结构,存储属于该线程的局部变量值。以下是 ThreadLocal 的底层实现原理:
ThreadLocal的结构
ThreadLocal主要由两个核心类组成:ThreadLocal本身和ThreadLocalMap。- 每个
Thread实例都有一个ThreadLocalMap,这个ThreadLocalMap存储着该线程所有ThreadLocal变量的值。 ThreadLocal的get()和set()方法会操作当前线程的ThreadLocalMap,以存取数据。
ThreadLocalMap内部结构
ThreadLocalMap是Thread类的一个内部类,每个Thread对象都持有一个ThreadLocalMap实例。ThreadLocalMap是一个自定义的哈希表结构,其键(key)是ThreadLocal对象的弱引用,值(value)是与该ThreadLocal对应的线程本地变量。
- 工作原理
- 当创建一个
ThreadLocal变量时,它不会直接存储在线程中,而是将其键值对(ThreadLocal对象和对应的值)存储在当前线程的ThreadLocalMap中。 - 当一个线程第一次调用
ThreadLocal的get()方法时,ThreadLocalMap会为该线程创建一个新的键值对,键是当前的ThreadLocal实例,值是线程局部变量的初始值。 - 后续访问该
ThreadLocal变量时,会使用当前线程的ThreadLocalMap直接获取或设置值。
- 弱引用的使用
- 在
ThreadLocalMap中,ThreadLocal的键是一个弱引用(WeakReference)。这意味着如果ThreadLocal对象本身没有其他强引用,它可以被垃圾回收。 - 如果
ThreadLocal对象被垃圾回收了,但线程还在运行,那么ThreadLocalMap中可能会存在一些过时的键值对,这些对在不清理的情况下会导致内存泄漏。 - 为了解决这个问题,在进行
get()、set()、remove()操作时,ThreadLocalMap会主动清理这些过时的键值对。
ThreadLocal的方法实现
get()方法:- 获取当前线程的
ThreadLocalMap。 - 根据
ThreadLocal对象查找相应的值。 - 如果没有找到,会调用
initialValue()方法(通常是返回null)来提供初始值,并将其存入ThreadLocalMap。
- 获取当前线程的
总结
ThreadLocal提供了线程本地存储的机制,确保每个线程都有其独立的变量副本,避免多线程环境中的数据竞争。- 底层实现依赖于每个线程持有的一个
ThreadLocalMap,该映射将ThreadLocal对象(弱引用)映射到线程局部变量的值。 - 内存泄漏风险:由于键是弱引用而值是强引用,必须手动调用
remove()清理不再需要的ThreadLocal,否则可能导致内存泄漏。
讲一讲Mysql联合索引
答:多个字段组成的索引,匹配时遵循最左匹配原则,然后讲了讲索引失效
联合索引
结构:
- 联合索引在内部存储时是按照 B+ 树 的结构来组织的,这种结构能够有效地支持范围查找和排序。
- B+ 树的每个节点存储的是索引列的值及其对应的数据指针(指向实际的数据行)。联合索引的节点根据索引列的顺序依次排列。
- 联合索引中的每一列都可以用于快速查找,但它的查找效率和顺序依赖于索引列的顺序。
创建联合索引:
- 联合索引可以由多个列组成,创建时指定列的顺序非常重要,因为 MySQL 会按照这个顺序进行排序和存储。例如:
1 | CREATE INDEX idx_name ON table_name (column1, column2, column3); |
以上语句创建了一个联合索引,索引的列顺序是 column1 -> column2 -> column3。
最左前缀原则:
MySQL 使用联合索引时遵循 最左前缀匹配原则。只有在查询中使用了联合索引的最左边列或最左连续列时,MySQL 才会使用这个联合索引。
例如,对于一个
1
(column1, column2, column3)
的联合索引:
- 查询
WHERE column1 = ?或WHERE column1 = ? AND column2 = ?可以使用索引。 - 查询
WHERE column2 = ?或WHERE column2 = ? AND column3 = ?无法使用索引,因为不满足最左前缀匹配。 - 查询
WHERE column1 = ? AND column3 = ?可以部分使用索引column1,但无法利用column3。
- 查询
覆盖索引:
- 当联合索引包含了查询所需的所有列时,称为 覆盖索引(Covering Index)。
- 覆盖索引查询可以直接在索引中找到所有需要的数据,而不需要回表查找实际的数据行,提高了查询效率。
联合索引的优缺点
联合索引的优缺点
优点:
- 提高查询效率:
- 对于多列组合查询,联合索引可以显著提高查询速度,尤其是当查询条件包含多个字段时。
- 减少索引数量:
- 一个联合索引可以替代多个单列索引,减少索引的数量,节省存储空间和维护成本。
- 支持多列的排序和过滤:
- 可以利用联合索引进行多列的排序(
ORDER BY)和过滤(WHERE),优化查询性能。
- 可以利用联合索引进行多列的排序(
缺点:
- 索引的顺序敏感:
- 联合索引的列顺序会影响其使用效果,查询必须按照索引的最左前缀进行匹配,灵活性较低。
- 插入和更新的性能影响:
- 每当插入、删除或更新数据时,索引都需要维护和更新,因此联合索引会增加插入、删除和更新操作的开销,尤其是在高并发的写入场景下。
- 占用更多存储空间:
- 联合索引会占用额外的磁盘空间,特别是在多列和大数据集的情况下,存储空间的需求较高。
常见的索引失效场景
常见的索引失效场景
1. 使用 OR 关键字
当查询中使用 OR 关键字连接的条件,且这些条件中的某一列没有索引时,整个索引可能会失效。例如:
1 | SELECT * FROM users WHERE first_name = 'John' OR last_name = 'Doe'; |
- 如果
first_name有索引,但last_name没有索引,则查询不会使用first_name的索引,导致全表扫描。
2. 使用不等于操作符(!= 或 <>)
使用 != 或 <> 操作符进行查询时,索引通常不会被使用。因为不等于操作符的性质决定了无法使用有序的索引结构快速定位数据。例如:
1 | SELECT * FROM users WHERE age != 30; |
- 索引无法高效查找不等于某个值的记录,因此会导致索引失效。
3. 使用函数或表达式
在查询条件中使用函数或表达式,数据库需要对每一行的数据进行计算,导致索引失效。例如:
1 | SELECT * FROM users WHERE UPPER(first_name) = 'JOHN'; |
- 使用了
UPPER()函数,索引失效。因为数据库需要对每个first_name值计算UPPER()后的结果,这导致无法使用原有的索引。
4. 数据类型不一致
如果查询条件中的列和给定的常量数据类型不一致,可能导致索引失效。例如,如果列是 INT 类型,而查询条件中使用了字符串类型的常量:
1 | SELECT * FROM users WHERE id = '123'; |
id是整数类型,但查询条件中的'123'是字符串类型,数据库在执行时需要进行类型转换,从而无法利用索引。
5. 使用 LIKE 模糊匹配
在使用 LIKE 查询时,如果匹配模式的开头是通配符 %,则索引失效。例如:
1 | SELECT * FROM users WHERE first_name LIKE '%ohn'; |
- 因为
%在前,数据库无法从索引中确定匹配的起始位置,因此需要进行全表扫描。 - 但如果是
LIKE 'John%',则索引是有效的,因为此时可以利用索引从John开始的部分快速查找。
6. 使用隐式转换
当查询条件中的列需要进行隐式类型转换时,索引也会失效。例如,age 列是 INT 类型,但条件中使用了字符串:
1 | SELECT * FROM users WHERE age = '25'; |
- 数据库会隐式地将
'25'转换为整数,然后进行比较,导致索引失效。
7. 范围查询
对于联合索引,使用范围查询(如 <, >, BETWEEN, LIKE)后,索引的后续列将失效。例如:
1 | SELECT * FROM users WHERE first_name = 'John' AND age > 30 AND city = 'New York'; |
- 如果有联合索引
(first_name, age, city),由于age > 30是范围查询,city列的索引会失效。
8. ORDER BY 和 GROUP BY 使用不当
- 如果
ORDER BY或GROUP BY的字段顺序与索引顺序不匹配,或包含的字段没有索引,可能导致索引失效。
1 | SELECT * FROM users ORDER BY first_name, age; |
- 如果索引是
(age, first_name),顺序不匹配,索引失效。
9. IS NULL 或 IS NOT NULL 查询
对于 NULL 值的查询,某些版本的 MySQL 可能不使用索引。例如:
1 | SELECT * FROM users WHERE first_name IS NULL; |
- 一些 MySQL 优化器不使用索引来处理
IS NULL查询,具体取决于 MySQL 版本和存储引擎
InnoDb为什么不用二叉树、B树而用B+树
InnoDb为什么不用二叉树、B树而用B+树
1. B+ 树的磁盘访问效率更高
- B+ 树 的所有数据节点都位于叶子节点,而内部节点仅存储索引键,结构更加紧凑。这种结构使得一个节点可以包含更多的键值,这样可以减少树的高度,降低磁盘 I/O 操作的次数。
- 传统的 二叉树 和 B 树 的每个节点不仅存储索引键,还存储数据本身,导致节点占用的存储空间较大,树的高度较高。这样在查找过程中需要更多的磁盘读取操作,性能会受到影响。
2. B+ 树的范围查询更高效
- B+ 树 的所有叶子节点通过指针相连,形成一个有序的链表,支持高效的范围查询(如
BETWEEN、<、>等)。- 例如,在执行
WHERE age BETWEEN 20 AND 30查询时,B+ 树只需要找到20的位置,然后沿着叶子节点顺序读取到30为止,性能非常高效。
- 例如,在执行
- 二叉树 和 B 树 没有链表结构,无法直接支持顺序遍历,每次范围查询都需要重新在树中查找,效率较低。
3. B+ 树的高度更低,平衡性更好
- B+ 树 的每个节点包含更多的索引键,树的高度更低,数据查询时需要的比较次数更少。因此,B+ 树 的平衡性更好,能够更快地定位到数据。
- 二叉树 容易退化成单链表(即最坏情况的时间复杂度是 O(n)),而 B 树 的内部节点存储的键值数量较少,导致树的高度较高,查找时也需要更多的比较次数。
4. B+ 树更适合磁盘存储结构
- 数据库的存储操作主要在磁盘上进行,磁盘的读写是基于块的(通常是 4KB 或 8KB)。B+ 树 的节点大小通常等于磁盘页的大小,这样一个节点可以一次性从磁盘读取到内存中,充分利用了磁盘预读特性。
- 二叉树 或 B 树 的节点存储的数据和索引混合在一起,节点大小不固定,无法很好地匹配磁盘页的大小,导致磁盘读取效率低下。
5. B+ 树更有利于缓存
- B+ 树 由于其非叶子节点仅存储键值,对缓存友好,因为同样大小的缓存可以存储更多的节点。更多的索引节点存储在内存中意味着更多的查找可以直接在内存中完成,从而减少磁盘 I/O,进一步提升性能。
- B 树 和 二叉树 存储的数据和索引在一起,导致每个节点占用的空间更大,内存缓存利用率更低。
6. B+ 树更适合顺序存储和区间查找
- B+ 树 的叶子节点按顺序连接,并且所有数据都在叶子节点上,这使得顺序访问和区间访问更加高效,非常适合数据库中的顺序扫描操作(如
ORDER BY操作)和范围查询。 - B 树 的数据分散在所有节点上,不能有效地利用顺序读取和区间扫描。
聚簇索引和非聚簇索引
聚簇索引(Clustered Index)
聚簇索引 是 InnoDB 默认使用的索引类型,表的主键通常会自动创建一个聚簇索引。聚簇索引将数据和索引存储在一起,每个表只能有一个聚簇索引。
特点:
- 数据与索引在一起存储:聚簇索引将实际的数据行存储在 B+ 树的叶子节点中。也就是说,索引的叶子节点就是数据本身,主键值决定数据的物理存储顺序。
- 按主键排序:聚簇索引根据主键的顺序将数据进行物理排序,因此主键查询和范围查询非常高效。
- 数据只能有一个物理顺序:由于数据存储和索引是绑定的,表只能有一个聚簇索引,通常是主键索引。
优点:
- 查询效率高:因为数据和索引在一起,按照主键进行查询时不需要二次查找,数据存取非常快。
- 范围查询效率高:由于数据按照主键顺序存储,范围查询(如
BETWEEN)可以直接从索引中读取一段连续的记录,非常高效。
缺点:
- 更新和插入成本较高:由于聚簇索引要求数据按主键顺序存储,插入新记录时可能会导致页分裂和移动操作,影响写入性能。
- 数据的物理顺序固定:如果经常进行非主键列的排序查询,聚簇索引可能不是最优选择。
适用场景:
- 表的主键查询频繁,或者进行大量的范围查询时,聚簇索引非常合适。
- 表的数据大小较为稳定,频繁的更新和插入操作较少。
非聚簇索引(Non-Clustered Index)
非聚簇索引 是指索引的叶子节点存储的是指向实际数据行的指针,而不是数据本身。非聚簇索引也称为 辅助索引(Secondary Index)。
特点:
- 索引和数据分开存储:非聚簇索引的叶子节点只存储索引值和指向实际数据的指针,而不是数据本身。查找数据时需要先查找索引,再通过指针找到对应的数据行。
- 可以有多个非聚簇索引:一个表可以创建多个非聚簇索引,针对不同的列进行索引,帮助加速不同类型的查询。
优点:
- 可以支持多种查询条件:非聚簇索引可以基于不同的列创建索引,因此可以加速不同的查询类型,不局限于主键查询。
- 不影响数据的物理存储顺序:由于非聚簇索引与数据分离,表的数据物理存储顺序不会受到非聚簇索引的影响。
缺点:
- 查询需要回表:在通过非聚簇索引查找数据时,首先需要根据索引找到数据的指针,然后再通过指针找到实际数据(回表操作)。这会增加一次磁盘 I/O,查询效率比聚簇索引低。
- 索引占用更多空间:由于非聚簇索引需要存储指针,它会占用更多的存储空间,尤其是创建了多个非聚簇索引的情况下。
适用场景:
- 需要加速非主键列的查询时,可以使用非聚簇索引。
- 表的查询频率较高,尤其是多条件查询和排序查询时,非聚簇索引非常适用。
对比
| 对比项 | 聚簇索引 (Clustered Index) | 非聚簇索引 (Non-Clustered Index) |
|---|---|---|
| 数据存储方式 | 数据和索引存储在一起,叶子节点就是数据 | 索引存储的是指向数据的指针,叶子节点存储索引和指针 |
| 数据顺序 | 数据按照主键顺序存储 | 数据和索引分离,数据存储顺序不受影响 |
| 查询性能 | 对主键查询或范围查询性能非常高,无需二次查找 | 需要回表查询,通过索引查找后还需访问数据,性能稍差 |
| 存储空间 | 只存储一次数据,无额外的指针占用 | 需要额外存储指针,占用更多的存储空间 |
| 数量限制 | 每个表只能有一个聚簇索引 | 每个表可以有多个非聚簇索引 |
| 适用查询类型 | 主键查询和范围查询 | 多列查询、排序查询、非主键查询 |
| 影响插入和更新 | 插入和更新时可能导致页分裂,影响性能 | 对插入和更新影响较小 |
总结
- 聚簇索引 适用于频繁进行主键查询和范围查询的表,可以提供非常高效的查询性能,但由于数据和索引绑定在一起,写入和更新性能可能受到影响。
- 非聚簇索引 则适用于对多个列进行查询加速的场景,虽然查询时可能需要回表,但它的灵活性和适用性更强,尤其适合复杂查询和多列查询。
讲一讲mysql的数据页page
数据页
数据页
数据页的基本概念
- 页 (Page) 的大小:
- InnoDB 默认的页大小是 16KB,即 16384 字节。这意味着每次从磁盘读取或写入时,最小的单位是 16KB,而不是单条记录。
- 页的大小可以根据配置进行调整,但大多数情况下默认使用 16KB。
- 页 (Page) 的类型:
- InnoDB 中有多种类型的页,负责存储不同类型的数据。例如:
- 数据页 (DATA PAGE):存储表的实际数据。
- 索引页 (INDEX PAGE):存储 B+ 树索引的节点。
- Undo 页:存储回滚信息。
- 系统页:存储表空间信息、事务信息等。
- LOB 页:用于存储大对象数据(如 BLOB、TEXT 字段)。
- InnoDB 中有多种类型的页,负责存储不同类型的数据。例如:
- 页 (Page) 的作用:
- 页是 InnoDB 在磁盘上分配存储空间的最小单位。通过页,InnoDB 将数据按照 16KB 的块进行管理,减少了频繁的磁盘 I/O,提高了数据访问效率。
- 每个页中可以存储多条记录。
数据页的结构
每个数据页(特别是数据存储页)内部由多个区域组成,主要部分包括:
- 文件头部 (File Header):
- 用于存储页的基本信息,如页类型、页的所属表空间、页的编号等。
- 页头部 (Page Header):
- 存储页的特定信息,如页中的记录数、页中的可用空间等。
- Infimum 和 Supremum 记录:
- 每个页中都包含两个特殊的伪记录,分别称为 Infimum和 Supremum。这些记录是页中记录的边界值,用来保证页中的记录有序。
- Infimum 是最小值伪记录。
- Supremum 是最大值伪记录。
- 每个页中都包含两个特殊的伪记录,分别称为 Infimum和 Supremum。这些记录是页中记录的边界值,用来保证页中的记录有序。
- 用户记录 (User Records):
- 存储实际的行数据。在数据页中,用户记录按照主键或索引顺序排列,形成一个双向链表。
- 每条记录都有一个指向下一条记录和上一条记录的指针(双向链表结构),以支持 B+ 树结构中的有序性。
- 页目录 (Page Directory):
- 用于加速记录的检索。由于记录在页内按顺序存储,页目录存储了记录的偏移量,方便快速定位某一范围内的记录。
- 页尾部 (Page Trailer):
- 包含校验和等信息,主要用于检测页是否被损坏。
数据页的使用
- 数据存储:
- 当 MySQL 需要存储一条记录时,InnoDB 会将这条记录写入适当的数据页。如果该页已满,InnoDB 会分裂该页并创建一个新的数据页。
- 数据页通过 B+ 树 结构来组织,页与页之间通过主键或索引顺序连接,形成一个有序的结构。
- 记录的插入、更新与删除:
- 插入:当插入新数据时,InnoDB 根据 B+ 树的结构找到合适的数据页进行插入。如果页已满,可能会触发页分裂,将一部分数据移动到新的页中。
- 更新:当更新数据时,如果新数据可以继续存储在当前页中,InnoDB 会直接更新;如果无法容纳,可能会移动到其他页中。
- 删除:当删除数据时,InnoDB 会标记该记录为空闲,而不立即释放该空间。
- 页的分裂与合并:
- 分裂:当一个页的数据已满,插入新数据时,会触发页分裂,将部分数据移到一个新的页中,从而保持树的平衡。
- 合并:当数据被大量删除后,如果某个页的利用率非常低,可能会触发页的合并操作,将数据合并到相邻的页中。
讲一讲MySQL事务的隔离级别
答:讲了那四种隔离级别,还有各自的优缺点
MySQL事务的隔离级别
隔离级别
1. 读未提交(Read Uncommitted)
特点:
- 最低的隔离级别,允许一个事务读取另一个事务尚未提交的数据。
- 可能出现 脏读(Dirty Read):一个事务读到了另一个事务尚未提交的修改数据,如果该事务随后回滚,那么这个读到的数据就是无效的。
问题:
- 脏读。
- 事务之间几乎没有隔离,数据不一致的可能性最大。
使用场景:
- 非常罕见的使用场景。通常为了追求极高的性能,但对数据一致性要求极低的系统才会使用。
2. 读已提交(Read Committed)
特点:
- 事务只能读取到 其他事务已经提交的数据,防止脏读。
- 是大多数数据库(如 Oracle)的默认隔离级别。
问题:
- 不可重复读(Non-repeatable Read):在同一个事务中,前后两次读取相同的数据,可能得到不同的结果,因为其他事务可能在这个过程中提交了更新。
使用场景:
- 适用于对数据一致性要求较低,但要求防止脏读的场景。
3. 可重复读(Repeatable Read)
特点:
- 确保在一个事务中的多次读取,读取到的数据是一致的,即 同一个事务中的相同查询结果是相同的,防止不可重复读。
- 是 MySQL 的默认隔离级别。
问题:
- 幻读(Phantom Read):当一个事务执行了某个范围内的查询后,另一个事务插入了数据,再次执行相同查询时,可能看到之前没有的“幻影”记录。InnoDB 通过 Next-Key Locking 机制防止幻读。
使用场景:
- 要求数据一致性高,且不希望在同一事务中读取到不同结果的场景。
4. 可串行化(Serializable)
特点:
- 最高的隔离级别,通过强制事务按顺序执行,完全避免脏读、不可重复读和幻读问题。
- 事务之间完全串行化执行,所有的数据操作都需要加锁,性能最差,尤其在高并发场景下会造成大量的锁竞争和性能瓶颈。
问题:
- 性能差,事务之间的并发性降低,可能导致大量锁等待和死锁。
使用场景:
- 对数据一致性要求极高的场景,但性能要求可以适当放宽,比如金融系统中的关键事务。
隔离级别对比总结
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-repeatable Read) | 幻读 (Phantom Read) | 性能 |
|---|---|---|---|---|
| 读未提交 (Read Uncommitted) | 可能 | 可能 | 可能 | 最高(并发性好) |
| 读已提交 (Read Committed) | 不可能 | 可能 | 可能 | 较高 |
| 可重复读 (Repeatable Read) | 不可能 | 不可能 | 可能 | 中等(默认) |
| 可串行化 (Serializable) | 不可能 | 不可能 | 不可能 | 最低(并发性差) |
总结
- 读未提交:性能最好,但数据一致性最差,会出现脏读。
- 读已提交:防止脏读,但可能出现不可重复读,适合大多数应用场景。
- 可重复读:防止脏读和不可重复读,但可能会出现幻读,是 MySQL 的默认隔离级别。
- 可串行化:隔离性最好,完全避免所有并发问题,但性能最差,适用于极端场景。
各隔离级别的实现原理
MySQL 中事务的隔离级别是通过 锁机制 和 MVCC(多版本并发控制) 实现的。
MVCC(多版本并发控制)
MVCC 是 MySQL 实现读已提交和可重复读隔离级别的核心机制。它通过为每个事务生成一个快照来保证数据的并发一致性。
Undo Log(回滚日志):MVCC 通过记录数据的历史版本(即未提交时的数据快照)来提供多个版本的数据。事务可以通过读取快照,确保看到的数据是一致的。
事务 ID(Transaction ID):每个事务都有一个唯一的事务 ID。在进行读操作时,InnoDB 会根据事务 ID 和数据版本来判断当前事务应该读取哪个版本的数据。
读视图(Read View):当一个事务开始时,InnoDB 会创建一个读视图,事务中的所有读操作都会基于这个视图,确保读到的数据版本是一致的。
读未提交(Read Uncommitted)
特点:
- 事务可以读取其他事务尚未提交的数据。
- 最低的隔离级别,可能导致脏读。
实现原理:
- 无锁读:在读未提交隔离级别下,读取数据时不会加锁,允许事务读取其他事务未提交的修改数据。
- 脏读问题:一个事务读取了另一个事务尚未提交的数据,且该数据可能会被回滚。读未提交下,InnoDB 并不使用 MVCC,所以直接读取当前最新的数据版本。
优点和问题:
- 性能较高,因为没有加锁机制,但数据不一致问题最严重,容易导致脏读问题。
读已提交(Read Committed)
特点:
- 事务只能读取到其他事务已经提交的数据,避免了脏读问题。
- 是 Oracle 的默认隔离级别。
实现原理:
- MVCC(多版本并发控制):MySQL 使用 MVCC 来实现读已提交隔离级别。每次查询时,事务会读取到最新的已提交数据(快照),不再读取未提交的数据。
- 快照读(Snapshot Read):读取时,使用的是已提交的最新数据快照,这意味着在同一个事务中,前后两次读取相同的行数据,可能看到不同的结果(即不可重复读问题)。
- 行级锁(Row Lock):当涉及到数据更新时,会对涉及的行进行加锁,确保其他事务在提交之前无法修改这些数据。
问题:
- 虽然解决了脏读问题,但因为每次读取的都是最新的已提交数据,所以仍然存在不可重复读的问题:同一事务的多次查询可能得到不同的结果。
可重复读(Repeatable Read)
特点:
- 保证一个事务中多次读取的数据是一致的,防止不可重复读。
- 是 MySQL 的默认隔离级别。
- 通过 MVCC 和 Next-Key Locking 防止幻读。
实现原理:
- MVCC 保证可重复读:
- 快照读(Snapshot Read):事务在第一次查询时,会创建一个一致性视图(快照)。在事务的整个生命周期中,所有的读操作都是基于这个快照进行的。因此,在同一个事务中,无论其他事务如何修改数据,当前事务读到的始终是这个快照中的数据,保证了可重复读。
- Next-Key Locking 防止幻读:
- 间隙锁(Gap Lock):在可重复读隔离级别下,MySQL 使用 Next-Key Locking,它是一种行锁和间隙锁的组合。在索引行上加锁时,不仅会锁住行本身,还会锁住行前后的间隙。这样可以防止其他事务在范围内插入新的记录,避免幻读问题。
- 幻读问题:在普通的 MVCC 机制中,虽然同一个事务中的多次读取可以返回一致的数据,但其他事务可能插入新的数据导致 “幻读”。Next-Key Locking 在行的索引范围上加间隙锁,避免了这种问题。
Next-Key Locking 的具体操作:
- 当对一组数据范围进行查询或修改时,InnoDB 会锁住满足条件的记录以及它们之间的间隙。这样即便其他事务在这些间隙中插入新的数据,也会被阻止,从而避免幻读。
总结:通过 MVCC 保证了不可重复读的解决,而通过 Next-Key Locking 防止了幻读,是 MySQL 默认推荐的隔离级别。
可串行化(Serializable)
特点:
- 最严格的隔离级别,完全避免脏读、不可重复读和幻读问题。
- 性能最差,因为事务之间基本是串行执行的。
实现原理:
- 强制加锁:
- 在可串行化隔离级别下,MySQL 会对所有读取操作都加锁,确保一个事务执行期间,其他事务无法修改或者插入数据。这包括对读取操作加共享锁(S Lock),对写操作加排他锁(X Lock)。
- 即使是简单的查询操作,也会锁住相关的数据,防止其他事务修改,确保事务之间的完全隔离。
- 加锁读(Locking Read):
- 每次读取数据时,都会对读取的数据加共享锁(S Lock),确保其他事务在当前事务结束前,不能对这些数据进行修改或者插入新数据。
- 性能问题:
- 因为每个事务都需要等到前一个事务完成后才能执行,所以可串行化隔离级别下,系统的并发性大大降低,导致性能下降。
总结:可串行化通过加锁来确保事务串行执行,避免了所有并发问题,但也牺牲了很大部分的性能,适用于对数据一致性要求极高的场景(如金融系统)。
总结
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-repeatable Read) | 幻读 (Phantom Read) | 实现机制 |
|---|---|---|---|---|
| 读未提交 (Read Uncommitted) | 可能 | 可能 | 可能 | 无锁,直接读取数据 |
| 读已提交 (Read Committed) | 不可能 | 可能 | 可能 | MVCC + 行锁 |
| 可重复读 (Repeatable Read) | 不可能 | 不可能 | 可能(通过 Next-Key Lock 解决) | MVCC + Next-Key Locking |
| 可串行化 (Serializable) | 不可能 | 不可能 | 不可能 | 强制加锁,确保串行执行 |
总结:
- 读未提交:通过无锁机制直接读取未提交数据,可能导致数据不一致(脏读)。
- 读已提交:使用 MVCC 保证只能读取已提交的数据,防止脏读,但仍然可能出现不可重复读。
- 可重复读:通过 MVCC 保证多次读取结果一致,并通过 Next-Key Locking 防止幻读,是 MySQL 默认隔离级别。
- 可串行化:通过加锁确保事务串行执行,防止所有并发问题,但性能代价较大。
讲一讲Spring事务
答:讲了隔离级别,比MySQL多了个默认的,还然后讲了Spring事务失效的场景。
Spring事务
Spring 事务管理方式
编程式事务管理
- 编程式事务是通过代码手动管理事务,在业务逻辑中明确地定义事务的开始、提交和回滚操作。通常通过
TransactionTemplate或PlatformTransactionManager实现。
1 | TransactionTemplate transactionTemplate = new TransactionTemplate(transactionManager); |
声明式事务管理
- 声明式事务是通过注解或 XML 配置的方式进行事务管理,无需显式在代码中控制事务边界。Spring AOP(面向切面编程)为声明式事务提供了支持,通常使用
@Transactional注解。
1 |
|
事务传播行为(Propagation)
Spring 事务有多个传播行为,控制当前方法调用时,事务如何传播。例如,在一个事务方法调用另一个事务方法时,是否继续使用当前事务,或开启新事务等。常见的传播行为包括:
- REQUIRED(默认):如果当前存在事务,则加入该事务;如果没有事务,则开启新事务。
- REQUIRES_NEW:总是新建一个事务,如果当前有事务,暂停当前事务。
- SUPPORTS:如果当前存在事务,则加入事务;如果没有事务,则以非事务方式运行。
- NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则挂起该事务。
- MANDATORY:必须存在一个事务,否则抛出异常。
- NEVER:以非事务方式运行,如果当前存在事务,抛出异常。
- NESTED:如果当前事务存在,则在嵌套事务内执行;否则,类似于 REQUIRED。
事务隔离级别
Spring 允许通过 @Transactional 注解配置事务的隔离级别,以控制事务之间的并发行为。支持的隔离级别与数据库的隔离级别一致:
- DEFAULT:使用底层数据库的默认隔离级别。
- READ_UNCOMMITTED:允许读取未提交的数据,可能导致脏读。
- READ_COMMITTED:只能读取已提交的数据,防止脏读。
- REPEATABLE_READ:确保同一事务内的多次读操作一致,防止不可重复读。
- SERIALIZABLE:最高的隔离级别,强制事务串行执行,防止脏读、不可重复读和幻读。
Spring事务失效场景
Spring事务失效场景
1. 事务方法是 private 或 final
Spring 事务是基于 AOP(面向切面编程)实现的,依赖于动态代理机制来拦截方法调用。如果方法是 private 或者 final,Spring 就无法通过代理进行拦截,因此事务不会生效。
- 原因:Spring AOP 默认通过代理对象的方式来拦截方法调用。而
private方法不可见,final方法不可被重写,导致代理无法工作,事务注解失效。 - 解决方法:确保事务方法是
public,并且类或者方法没有被final修饰。
2. 自调用(内部方法调用)
当一个类内部的非事务方法调用同一个类中的事务方法时,Spring 事务不会生效。这是因为 Spring 的 AOP 代理只拦截外部对该类的调用,内部调用不会通过代理类,因此事务注解不会被触发。
- 原因:自调用跳过了代理对象,直接调用了目标方法,Spring AOP 无法介入。
- 解决方法:
- 将事务方法放在另一个被 Spring 管理的 Bean 中。
- 通过注入自身的代理对象调用该事务方法。
3. 异常没有触发事务回滚
Spring 默认只对 RuntimeException(非检查异常) 或 Error 触发回滚。如果事务方法抛出的是 Checked Exception(检查异常),则不会自动回滚,导致事务失效。
- 原因:Spring 默认配置只对
RuntimeException及其子类进行回滚,而不回滚Checked Exception。 - 解决方法:
- 在
@Transactional注解中显式声明回滚的异常类型,如rollbackFor。
- 在
4. @Transactional 注解没有在接口或类上
Spring 的事务是通过代理对象来管理的,通常 @Transactional 应该注解在公开的接口或实现类的 public 方法上。如果注解在非 public 方法上,事务将无法生效。
- 原因:Spring 事务依赖 AOP 拦截公开方法,非
public方法不会触发代理。 - 解决方法:确保
@Transactional注解在public方法上。
5.传播行为设置不当
事务的传播行为会影响事务的生效方式。如果传播行为设置不当(如设置为 Propagation.NOT_SUPPORTED 或 Propagation.NEVER),即使在事务方法中也可能导致事务失效。
- 原因:传播行为指定了事务的执行规则,如
NOT_SUPPORTED表示方法应该在非事务环境下执行,这会导致事务失效。 - 解决方法:根据业务场景正确设置事务的传播行为。
6. 数据库不支持事务
Spring 事务管理依赖于底层数据库的事务支持。如果底层数据库或数据源(如 MyISAM 存储引擎)不支持事务操作,那么即使在代码中配置了事务,也不会生效。
- 原因:底层数据库不支持事务或表引擎不支持事务(如 MySQL 中的
MyISAM表)。 - 解决方法:确保使用支持事务的数据库引擎(如 MySQL 的
InnoDB)。
7.多线程场景
Spring 事务是基于线程绑定的(ThreadLocal)。如果事务方法在一个线程中启动,随后在另一个线程中继续执行,那么事务将不会继续传播到新的线程中,这会导致事务失效。
- 原因:Spring 事务是与当前线程绑定的,不会自动在新的线程中生效。
- 解决方法:
- 避免在多线程中直接使用 Spring 事务。
- 如果必须使用多线程,应该在每个线程中独立管理事务。
8. 未使用 Spring 管理的 Bean
事务只有在 Spring 管理的 Bean 中才能生效。如果事务方法所在的类不是由 Spring 容器管理的(例如手动创建的类实例),事务将不会生效。
- 原因:Spring 的事务管理通过 AOP 实现,必须依赖 Spring 容器进行管理。
- 解决方法:确保事务方法所在的类是由 Spring 容器管理的,即通过
@Component、@Service等注解或 XML 配置进行管理。
9.未配置事务管理器
Spring 事务需要一个 PlatformTransactionManager 来管理事务的生命周期。如果没有正确配置事务管理器,事务也不会生效。
- 原因:缺少事务管理器的配置,Spring 无法管理事务。
- 解决方法:确保正确配置了事务管理器,通常使用
DataSourceTransactionManager或其他具体的事务管理器。
10. 嵌套事务导致事务失效
在嵌套事务中,如果传播行为设置不当(如 NESTED 或 REQUIRES_NEW),可能会导致外部事务的提交或回滚与内部事务的执行顺序不一致,导致事务失效。
- 原因:嵌套事务的传播行为控制不当,导致内部事务回滚时无法影响外部事务。
- 解决方法:仔细设计嵌套事务的传播行为,确保事务边界和传播符合预期。
下面是另一场面试,面试官搞C的,问的计网,基本不会😭😭😭
说一说常用的linux指令
文件和目录操作
ls:列出目录内容
ls -l:显示详细信息ls -a:显示隐藏文件
cd:切换目录
cd /path/to/dir:进入指定目录cd ..:返回上一级目录
pwd:显示当前工作目录
mkdir:创建目录
mkdir newdir:创建一个名为newdir的目录
rmdir:删除空目录
rmdir dir:删除目录dir
cp:复制文件或目录
cp file1 file2:复制file1到file2cp -r dir1 dir2:复制目录dir1到dir2
mv:移动或重命名文件/目录
mv file1 file2:将file1重命名为file2mv file /path/to/dir:将file移动到指定目录
rm:删除文件或目录
rm file:删除文件rm -r dir:删除目录及其内容rm -f file:强制删除文件
touch:创建空文件或更新文件的时间戳
touch newfile:创建一个名为newfile的空文件
cat:查看文件内容
cat file:输出文件内容cat file1 file2:将多个文件内容合并输出
more/less:分页查看文件内容
less file:分页查看file内容more file:简单分页查看
head:显示文件的前几行
head -n 10 file:显示文件file的前 10 行
tail:显示文件的后几行
tail -n 10 file:显示文件file的最后 10 行tail -f file:实时监控文件内容变化
用户和权限管理
whoami:显示当前用户
who:显示当前登录的所有用户
su:切换用户
su username:切换到指定用户su -:切换到超级用户(root)
chmod:更改文件权限
chmod 755 file:设置文件file的权限为 755(rwxr-xr-x)chmod +x file:给文件file增加执行权限
chown:更改文件所有者
chown user file:将文件file的所有者改为userchown user:group file:更改文件的所有者和所属组
passwd:修改用户密码
passwd:修改当前用户密码passwd username:修改指定用户的密码(需要超级用户权限)
系统信息和管理
df:显示磁盘使用情况
df -h:以人类可读的形式显示磁盘使用
du:显示目录或文件的大小
du -h file:以人类可读的形式显示文件file的大小du -sh dir:显示目录dir的总大小
free:显示内存使用情况
free -h:以人类可读的形式显示内存信息
uname:显示系统信息
uname -a:显示详细的系统信息(内核版本、主机名等)
top:动态显示系统的实时进程信息
top:查看 CPU、内存使用率和进程信息
ps:显示当前系统的进程信息
ps aux:列出所有进程
kill:终止进程
kill PID:终止指定进程号PID的进程kill -9 PID:强制终止进程
uptime:显示系统的运行时间、当前时间和负载
hostname:显示或设置系统的主机名
网络管理
ifconfig:显示或配置网络接口信息(部分现代系统使用 ip 代替)
ifconfig:查看网络接口信息
ping:测试网络连通性
ping www.google.com:测试与google.com的连通性
netstat:显示网络连接和端口状态
netstat -tuln:显示当前监听的 TCP 和 UDP 端口
ss:显示网络连接状态(比 netstat 更现代的工具)
ss -tuln:显示当前监听的端口
curl:发送网络请求
curl www.example.com:请求example.com的主页
wget:下载文件
wget http://example.com/file:下载指定 URL 的文件
压缩和解压缩
tar:打包与解包文件
tar -czvf archive.tar.gz dir:将目录dir打包为archive.tar.gztar -xzvf archive.tar.gz:解压缩archive.tar.gz
zip/unzip:压缩与解压缩 ZIP 文件
zip archive.zip file1 file2:将文件file1和file2压缩为archive.zipunzip archive.zip:解压缩archive.zip
查找文件
find:在目录中查找文件
find /path -name filename:在/path目录下查找名为filename的文件
grep:在文件中查找文本内容
grep 'pattern' file:在文件file中查找匹配pattern的行grep -r 'pattern' dir:递归查找目录dir中的文件
其他常用命令
history:显示历史命令记录
history:显示所有历史命令
alias:创建命令别名
alias ll='ls -l':创建ll别名执行ls -l
echo:输出文本或变量值
echo "Hello World":输出字符串Hello Worldecho $PATH:显示PATH环境变量
date:显示或设置系统日期和时间
date:显示当前日期和时间
shutdown:关机或重启
shutdown -h now:立即关机shutdown -r now:立即重启
在链表中如何找到最中间的节点
答:分有环无环,无环就用快慢指针,有环就找环(快慢指针)定长取中间
无环
快慢指针”(Fast and Slow Pointers)。这种方法的核心思想是使用两个指针同时遍历链表:一个快指针每次移动两步,慢指针每次移动一步。当快指针到达链表末尾时,慢指针正好到达链表的中间节点。
算法步骤:
- 初始化两个指针:将“慢指针”(
slow)和“快指针”(fast)都指向链表的头节点。 - 遍历链表:
slow每次向前移动一步。fast每次向前移动两步。
- 结束条件:
- 当
fast指针到达链表末尾(即fast == null或fast.next == null)时,slow指针所指的节点就是链表的中间节点。
- 当
代码示例:
1 | class ListNode { |
时间复杂度和空间复杂度:
- 时间复杂度:
O(n),只需要遍历链表一次。 - 空间复杂度:
O(1),只使用了常量级的额外空间。
有环
步骤:
- 检测环:
- 使用“快慢指针”方法来检测链表中是否有环。如果两个指针相遇,说明链表有环。
- 找到环的起点:
- 在检测到环之后,可以通过另外一个慢指针从头节点开始,和当前慢指针一起移动,找到环的起点。
- 找到中间节点:
- 重新应用“快慢指针”方法来找到环的中间节点。注意处理环中的节点数量计算。
详细步骤和代码:
1. 检测环
使用快慢指针方法检测链表是否有环。
1 | public boolean hasCycle(ListNode head) { |
2. 找到环的起点
如果链表有环,使用两个指针找到环的起点。
1 | public ListNode detectCycle(ListNode head) { |
3. 找到环中的中间节点
在找到环的起点后,可以计算环的长度,然后找到中间节点。
1 | public ListNode findMiddleOfCycle(ListNode head) { |
总结:
- 检测环:使用快慢指针检测环的存在。
- 找到环的起点:使用另一个指针从头节点开始寻找环的起点。
- 找到环中的中间节点:计算环的长度,然后找到中间节点。
如何用栈实现一个队列
答:用两个栈模拟……
如何用栈实现一个队列
思路:
- 使用两个栈来模拟队列,一个栈(
stack1)用于入队操作,另一个栈(stack2)用于出队操作。 - 入队操作:将元素压入
stack1。 - 出队操作:如果
stack2为空,则将stack1中的所有元素逐个弹出并压入stack2,然后在stack2中弹出元素。
操作解析
- 入队(
enqueue):- 直接将元素压入
stack1。
- 直接将元素压入
- 出队(
dequeue):- 如果
stack2为空,将stack1中的所有元素逐个弹出并压入stack2。然后从stack2中弹出元素。这样可以保证stack2中的元素顺序符合队列的先进先出原则。
- 如果
- 查看队列的第一个元素(
peek):- 同样,如果
stack2为空,将stack1中的所有元素移动到stack2,然后返回stack2的顶部元素。
- 同样,如果
- 检查队列是否为空(
isEmpty):- 当两个栈都为空时,队列为空。
性能分析
- 入队操作:每次操作的时间复杂度为
O(1)。 - 出队操作:最坏情况下,
stack1中的所有元素都需要被移动到stack2中,因此时间复杂度为O(n),但每个元素只会被移动一次,所以摊销时间复杂度为O(1)。 - 空间复杂度:两个栈中存储的元素总数不变,所以空间复杂度为
O(n),其中n是队列中元素的总数。
进程和线程
进程和线程有什么区别
进程和线程的区别
1. 基本概念
- 进程:是操作系统进行资源分配和调度的基本单位。每个进程都有独立的内存空间、文件描述符和其他资源。进程间的隔离可以确保一个进程的崩溃不会影响到其他进程。
- 线程:是进程中的一个执行单元。线程共享进程的内存空间和资源,但每个线程有自己的执行栈和程序计数器。线程间的切换比进程间的切换更高效,因为线程间的上下文切换不涉及内存的重新映射。
2. 资源占用
- 进程:
- 拥有独立的内存空间和资源。
- 创建进程的开销较大,因为需要分配独立的资源。
- 进程间的通信(IPC)通常需要更多的操作和开销,例如管道、消息队列或共享内存。
- 线程:
- 线程共享进程的内存空间和资源。
- 创建线程的开销较小,因为线程共享进程的资源。
- 线程间的通信更为直接,因为它们共享同一进程的内存空间。
3. 调度和切换
- 进程:
- 进程调度由操作系统的内核进行,切换进程涉及到较大的上下文切换开销,因为需要保存和恢复进程的上下文信息(如内存映射、寄存器状态等)。
- 线程:
- 线程调度通常由操作系统的内核或用户级线程库进行。线程切换的开销较小,因为线程共享同一进程的内存空间,不需要切换内存映射。
4. 错误隔离
- 进程:
- 进程之间的隔离程度高,一个进程的崩溃不会直接影响其他进程。这种隔离性提高了系统的稳定性。
- 线程:
- 线程之间的隔离性较低,一个线程的崩溃可能会影响整个进程中的其他线程。这是因为线程共享进程的内存和资源。
5. 使用场景
- 进程:
- 适用于需要高度隔离的应用程序或服务。例如,操作系统中的各个应用程序、数据库服务等。
- 线程:
- 适用于需要并发处理的任务,但这些任务共享同一资源。例如,Web 服务器处理多个用户请求,或在计算密集型任务中进行并行计算。
总结
- 进程是资源分配的基本单位,拥有独立的内存空间和资源,进程间隔离较高,但创建和切换开销较大。
- 线程是进程中的执行单元,共享进程的内存和资源,线程间切换开销小,但隔离性较差,适合需要并发处理的任务。
进程和线程之间的通信方式
进程间通信(IPC)
进程间通信(IPC)用于在不同进程之间传递数据或消息。由于进程具有独立的内存空间,因此它们需要通过特定的机制来交换信息。常见的 IPC 方式包括:
- 管道(Pipes):
- 匿名管道:用于父子进程之间的通信。数据从一个进程写入管道,然后由另一个进程读取。匿名管道是单向的。
- 命名管道(FIFO):可以用于任何两个进程之间的通信,不限于父子进程。命名管道是双向的。
- 消息队列(Message Queues):
- 消息队列允许进程将消息发送到队列中,接收进程从队列中读取消息。这种方式支持多对多通信,且可以设置消息的优先级。
- 共享内存(Shared Memory):
- 允许多个进程共享同一块内存区域,以便快速交换数据。需要使用同步机制(如信号量)来避免并发冲突。
- 信号量(Semaphores):
- 信号量用于协调进程间对共享资源的访问,以避免冲突。信号量可以用于实现互斥和同步。
- 套接字(Sockets):
- 套接字用于在网络上的不同主机或同一主机的不同进程之间进行通信。常用于分布式系统中。
- 文件映射(Memory-Mapped Files):
- 将文件映射到进程的虚拟地址空间中,从而允许不同进程通过访问共享文件来通信。
线程间通信
线程间通信(也称为线程同步)通常较为简单,因为线程共享进程的内存空间。常见的线程间通信和同步机制包括:
- 共享内存:
- 线程直接访问共享的内存区域。由于线程共享相同的内存空间,它们可以通过读写共享数据来进行通信。
- 互斥锁(Mutexes):
- 用于保护共享资源,防止多个线程同时访问造成数据不一致。常见的互斥锁包括互斥量(
pthread_mutex_t)和同步锁(synchronized)。
- 用于保护共享资源,防止多个线程同时访问造成数据不一致。常见的互斥锁包括互斥量(
- 条件变量(Condition Variables):
- 用于在特定条件下等待或通知线程。条件变量通常与互斥锁配合使用,以实现复杂的同步逻辑。
- 信号量(Semaphores):
- 用于控制对共享资源的访问,允许多个线程同时访问有限数量的资源。信号量可以用于实现线程的同步和协调。
- 读写锁(Read-Write Locks):
- 允许多个线程同时读共享资源,但在写操作时需要独占访问。读写锁在读操作频繁的场景中比互斥锁更高效。
- 消息队列(Message Queues):
- 在某些编程语言和库中,线程间可以使用消息队列来发送和接收消息。这种方式也可以用于线程间的通信。
- 事件(Events):
- 用于线程间的信号通知。一个线程可以等待事件的触发,而另一个线程则可以设置事件。
总结
进程间通信(IPC):由于进程间的内存隔离,需要使用管道、消息队列、共享内存、信号量、套接字等机制来进行通信。
线程间通信:由于线程共享进程的内存空间,可以直接通过共享内存进行通信,通常还需要使用互斥锁、条件变量、信号量等同步机制来管理并发访问。
CPU指令集
CPU指令集
基本概念
- 指令集(Instruction Set):一组由CPU执行的基本操作指令。指令集定义了CPU可以执行哪些操作,比如算术运算、逻辑运算、数据传输等。
- 指令格式:指令集中的每条指令都有一个特定的格式,通常包括操作码(opcode)和操作数(operand)。操作码指定了要执行的操作,操作数指定了操作的数据或操作的数据的位置。
指主要功能
- 数据处理:包括算术运算(加、减、乘、除)、逻辑运算(与、或、非)、位操作(左移、右移)。
- 数据传输:包括从内存加载数据到寄存器、将数据从寄存器存储到内存。
- 控制流:包括跳转、分支、函数调用和返回,用于控制程序的执行路径。
- 输入输出:控制与外部设备的数据交换。
- 系统控制:管理系统状态和处理异常情况。
指令集设计的影响
- 性能:指令集的复杂性和设计影响CPU的执行效率和速度。
- 兼容性:不同的指令集架构之间不兼容,意味着编写的程序只能在支持相应指令集的处理器上运行。
- 功耗:简化的指令集通常会导致更低的功耗,适合于移动设备和嵌入式系统。
常见的指令集架构
x86
- 描述:由Intel最初设计,广泛用于个人计算机。x86指令集包含了大量的指令和功能,用于处理各种操作。
- 特点:
- 复杂指令集计算(CISC):支持多种复杂指令,每条指令可以执行多个操作。
- 多模式:支持实模式、保护模式、虚拟模式等不同的操作模式。
ARM
- 描述:由ARM Holdings设计,广泛用于嵌入式系统、智能手机、平板电脑等。ARM指令集被广泛应用于移动设备和低功耗设备中。
- 特点:
- 精简指令集计算(RISC):指令集简洁,主要执行简单的操作,设计以提高执行效率。
- 功耗优化:高效能低功耗设计,使其适合于移动和嵌入式设备。
MIPS
- 描述:由MIPS Computer Systems设计,主要用于学术研究、嵌入式系统和一些商业产品中。
- 特点:
- RISC:设计简洁,指令集以高效的流水线执行为目标。
- 清晰的指令格式:易于教学和理解。
RISC-V
- 描述:一种开源的RISC指令集架构,旨在成为一个灵活且可扩展的指令集。
- 特点:
- 开源:可以自由使用和修改,没有许可费用。
- 模块化:基础指令集简单,可以扩展以支持额外功能。
虚拟内存
虚拟内存
基本概念
- 虚拟地址空间:每个进程都被分配一个虚拟地址空间,这些地址与实际的物理内存地址是不同的。进程的内存地址是虚拟的,不直接对应于实际的物理地址。
- 分页(Paging):虚拟内存通过将内存划分为固定大小的块(页)来管理。分页机制将虚拟地址空间分成若干个页(通常是4KB),每个页可以映射到物理内存中的页框(Page Frame)。
- 页面表(Page Table):操作系统维护一个页面表,它记录虚拟页到物理页框的映射关系。页面表用于将虚拟地址转换为物理地址。
- 页面置换(Page Replacement):当物理内存不足时,操作系统会将不常用的页面从物理内存中移到磁盘上的交换空间(Swap Space),释放内存给当前需要使用的页面。这一过程称为页面置换。
- 换入(Page In)和换出(Page Out):当一个页面被移到磁盘后,如果进程再次需要该页面,则需要将其从磁盘中加载回物理内存,这称为换入;相反,从物理内存中移到磁盘称为换出。
主要优点
- 扩展内存:允许程序使用比物理内存更多的内存,提升程序的运行能力。
- 隔离进程:每个进程拥有自己的虚拟地址空间,进程间不会互相干扰,提高了系统的稳定性和安全性。
- 内存保护:通过虚拟内存机制,操作系统可以防止一个进程访问另一个进程的内存区域,增强系统的安全性。
- 高效利用内存:操作系统可以将不常用的页面移到磁盘上,优化物理内存的使用。
实现机制
- 地址转换:
- 硬件支持:现代CPU通常有内置的内存管理单元(MMU),用于快速将虚拟地址转换为物理地址。
- 软件支持:操作系统管理页面表,并处理地址转换和页面置换。
- 页面表:
- 页表项(Page Table Entry, PTE):包含虚拟页到物理页框的映射信息,可能还包括权限位(读、写、执行权限)和状态位(如是否在内存中)。
- 内存分页算法:
- FIFO(先进先出):最早进入内存的页面最先被置换。
- LRU(最近最少使用):最久未使用的页面最先被置换。
- CLOCK(时钟算法):基于页面的使用时间来决定置换页面。
开销
- 性能开销:虚拟内存的地址转换和页面置换操作可能导致性能开销,尤其是在页面频繁换入换出的情况下,可能会引发“交换抖动”(Thrashing)。
- 内存使用开销:维护页面表和交换空间会消耗一定的内存和存储资源。
OSI七层模型
OSI七层模型
OSI七层模型(Open Systems Interconnection Model)是一种网络体系结构模型,用于标准化计算机网络的通信协议和功能。它由国际标准化组织(ISO)定义,将网络通信分成七个层次,每一层都完成特定的功能,并与相邻层进行交互。这种分层模型帮助实现了网络设备和协议的互操作性、模块化设计以及故障排除。
OSI七层模型的七层
- 物理层(Physical Layer):
- 功能:定义了物理连接的电气、机械、程序和功能特性。负责将数据转换为电信号、光信号或无线信号。
- 示例:网卡、集线器、传输介质(如电缆、光纤)、信号编码。
- 数据链路层(Data Link Layer):
- 功能:提供物理地址寻址、错误检测和纠正。将数据打包为帧并在物理网络上进行传输。
- 示例:以太网、Wi-Fi、交换机、MAC地址。
- 网络层(Network Layer):
- 功能:负责将数据从源主机传输到目的主机,进行路径选择和逻辑地址寻址(如IP地址)。
- 示例:IP协议、路由器、IP地址、路由选择(如RIP、OSPF)。
- 传输层(Transport Layer):
- 功能:提供端到端的通信,确保数据的可靠传输和流量控制。负责分段和重组数据,并进行错误检测和修正。
- 示例:TCP、UDP、端口号、流量控制、差错检测。
- 会话层(Session Layer):
- 功能:管理会话连接,建立、维护和终止进程间的会话。负责会话的同步和恢复。
- 示例:会话恢复、会话管理、API(如NetBIOS)。
- 表示层(Presentation Layer):
- 功能:负责数据的格式转换、加密和解密。确保不同系统之间的数据能够正确理解。
- 示例:数据编码(如ASCII、EBCDIC)、加密、解密、数据压缩。
- 应用层(Application Layer):
- 功能:直接与应用程序交互,提供网络服务和接口。处理应用程序的数据传输、协议和网络服务。
- 示例:HTTP、FTP、SMTP、DNS、Web浏览器、电子邮件客户端。
分层模型的优点
- 模块化设计:每一层都专注于特定功能,简化了设计和开发,使得每一层的功能独立、易于管理和维护。
- 互操作性:不同厂商的设备和协议可以在相同的层次上进行通信,确保了不同系统和设备间的兼容性。
- 故障排除:分层模型使得网络问题可以在具体的层次上进行定位和解决,从而简化了故障排查过程。
- 协议独立性:各层协议可以独立发展和升级,而不影响其他层的功能,实现了协议的灵活性和扩展性。
常用的网络协议
应用层协议
HTTP(Hypertext Transfer Protocol):
- 用途:用于在Web浏览器和Web服务器之间传输网页和资源。
- 特点:无状态协议,基于请求-响应模式。
HTTPS(HTTP Secure):
- 用途:HTTP的安全版本,通过SSL/TLS加密传输数据。
- 特点:提供数据加密和安全传输。
FTP(File Transfer Protocol):
- 用途:用于在客户端和服务器之间传输文件。
- 特点:支持文件上传和下载,有两种模式:主动模式和被动模式。
SMTP(Simple Mail Transfer Protocol):
- 用途:用于电子邮件的发送。
- 特点:基于文本的协议,用于发送邮件到邮件服务器。
POP3(Post Office Protocol 3):
- 用途:用于从邮件服务器下载邮件到本地客户端。
- 特点:邮件下载后通常从服务器上删除。
IMAP(Internet Message Access Protocol):
- 用途:用于访问和管理存储在邮件服务器上的邮件。
- 特点:邮件可以在服务器上保留,支持多设备访问。
DNS(Domain Name System):
- 用途:将域名转换为IP地址。
- 特点:分布式数据库,提供域名解析服务。
传输层协议
TCP(Transmission Control Protocol):
- 用途:提供可靠的、面向连接的数据传输服务。
- 特点:保证数据的顺序和完整性,支持流量控制和拥塞控制。
UDP(User Datagram Protocol):
- 用途:提供无连接的、简单的数据传输服务。
- 特点:没有重传机制,适用于对实时性要求高但对丢包容忍的应用,如视频流和游戏。
网络层协议
IP(Internet Protocol):
- 用途:提供网络层的地址和路由功能,用于将数据包从源地址传输到目的地址。
- 特点:有IPv4和IPv6两种版本,IPv6支持更大的地址空间。
ICMP(Internet Control Message Protocol):
- 用途:用于网络设备之间传递控制消息和错误报告。
- 特点:常用于网络故障诊断,例如ping命令。
数据链路层协议
Ethernet:
- 用途:广泛用于局域网(LAN)中进行数据传输。
- 特点:基于帧的传输,支持不同的速度(如10/100/1000 Mbps)。
Wi-Fi:
- 用途:用于无线局域网(WLAN)中的数据传输。
- 特点:提供无线连接,常用于家庭和办公网络。
PPP(Point-to-Point Protocol):
- 用途:用于串行连接中的数据链路层协议,例如拨号上网。
- 特点:支持认证、加密和压缩。
物理层协议
DSL(Digital Subscriber Line):
- 用途:通过电话线路提供高速互联网接入。
- 特点:支持同时传输语音和数据。
光纤(Fiber Optics):
- 用途:通过光纤提供高速的数据传输。
- 特点:带宽高,传输距离远,抗干扰性强。
TCP
TCP首部有哪些信息
TCP首部的主要字段
源端口号(Source Port):发送数据的端口号。
目的端口号(Destination Port):接收数据的端口号。
序列号(Sequence Number):标识数据的顺序。
确认号(Acknowledgment Number):确认收到的数据的下一个序列号。
数据偏移(Data Offset):TCP首部的长度。
标志位(Flags):控制连接状态,例如:
- SYN:开始连接。
- ACK:确认收到数据。
- FIN:结束连接。
窗口大小(Window Size):接收方能接收的数据量。
校验和(Checksum):检测数据传输中的错误。
紧急指针(Urgent Pointer):标识紧急数据的位置(如果有的话)。
TCP三次握手过程
TCP三次握手过程
TCP三次握手(Three-Way Handshake)是建立TCP连接的过程,用于确保双方都准备好进行数据传输。这个过程涉及三个主要的步骤:
1. 第一步:SYN
- 客户端发送一个SYN(同步)标志位的数据包到服务器,请求建立连接。这个数据包中包含一个初始的序列号(Initial Sequence Number, ISN)。
- 操作:客户端发送SYN包,状态变为SYN_SENT。
2. 第二步:SYN-ACK
- 服务器收到SYN包后,回复一个包含SYN和ACK(确认)标志位的数据包,确认收到客户端的请求,并同时发送自己的SYN请求。这个数据包中包含服务器的初始序列号。
- 操作:服务器发送SYN-ACK包,状态变为SYN-RECEIVED。
3. 第三步:ACK
- 客户端收到SYN-ACK包后,发送一个确认ACK包,确认服务器的SYN请求。此时,客户端和服务器的序列号都已确认。
- 操作:客户端发送ACK包,状态变为ESTABLISHED(已建立连接)。
总结
- 客户端 → 发送SYN包(请求连接)。
- 服务器 → 发送SYN-ACK包(确认连接)。
- 客户端 → 发送ACK包(完成连接)。
完成三次握手后,TCP连接建立,客户端和服务器可以开始数据传输。这个过程确保双方都准备好并能进行有效的通信。
SYN标志位有什么用
SYN标志位
1. 初始化连接
- 连接请求:客户端在向服务器发起连接时,会发送一个带有SYN标志位的数据包。这个数据包表示客户端希望建立一个新的连接,并且包含客户端的初始序列号(Initial Sequence Number, ISN)。
2. 同步序列号
- 同步序列号:SYN标志位的数据包还包含一个初始序列号。这个序列号用于同步双方的序列号计数器,以确保数据的正确排序和完整性。双方在连接建立过程中会交换自己的序列号,以便后续的数据传输可以正确地进行排序和确认。
3. 连接确认
- 确认连接:服务器收到客户端的SYN包后,会回复一个SYN-ACK包,表示接受连接请求,并发送自己的初始序列号。服务器通过SYN-ACK包中的SYN标志位确认它也希望建立连接,并且ACK标志位确认收到客户端的SYN包。
4. 握手过程
- 三次握手:SYN标志位的使用是三次握手的第一步,通过这种方式,客户端和服务器能够确保双方都准备好进行数据传输。客户端通过SYN包发起连接请求,服务器通过SYN-ACK包确认连接请求,客户端再通过ACK包确认连接建立。
HTTP和HTTPS是什么
HTTP和HTTPS是什么
HTTP(Hypertext Transfer Protocol)和HTTPS(Hypertext Transfer Protocol Secure)都是用于在网络上进行数据传输的协议,但它们在安全性方面有显著的区别。
HTTP(Hypertext Transfer Protocol)
- 功能:HTTP是用于在客户端(如浏览器)和服务器之间传输网页和其他资源的协议。它采用请求-响应模式,客户端发起请求,服务器返回响应。
- 特点:
- 无状态:每次请求都是独立的,服务器不会记住之前的请求状态。
- 明文传输:数据以明文形式传输,容易被中间人(如黑客)拦截和读取。
- 端口号:默认使用80端口。
- 使用场景:适用于对安全性要求不高的场景,如普通的网站浏览和访问。
HTTPS(Hypertext Transfer Protocol Secure)
- 功能:HTTPS是在HTTP的基础上加入了加密层(SSL/TLS),用于加密数据传输,提高数据的安全性。
- 特点:
- 加密传输:使用SSL/TLS协议加密数据,确保数据在传输过程中不被窃听或篡改。
- 身份验证:通过数字证书验证服务器的身份,防止中间人攻击。
- 数据完整性:确保数据在传输过程中不会被修改。
- 端口号:默认使用443端口。
- 使用场景:适用于对安全性要求较高的场景,如在线支付、账户登录、敏感数据传输等。
总结
- HTTP是用于网页传输的标准协议,但不提供加密和安全保护。
- HTTPS在HTTP的基础上增加了加密和身份验证功能,提供了更高的安全性,广泛用于需要保护数据隐私和安全的场景。
HTTPS怎么实现加密的
HTTPS加密原理
HTTPS通过使用SSL(Secure Sockets Layer)或其后继者TLS(Transport Layer Security)协议来实现加密,确保客户端与服务器之间的数据传输是安全的。整个加密过程主要依赖于对称加密、非对称加密和数字证书的组合来保护数据。以下是HTTPS加密的实现过程:
1. 非对称加密(公钥/私钥)
HTTPS使用非对称加密算法来进行身份验证和密钥交换。非对称加密使用一对密钥:公钥和私钥。公钥用于加密,私钥用于解密。
2. 对称加密(会话密钥)
在HTTPS连接中,实际的数据传输是通过对称加密进行的。对称加密使用同一个密钥来加密和解密数据,因此加密和解密效率更高。这个对称密钥是在握手过程中协商出来的。
HTTPS加密过程(TLS/SSL握手流程)
1. 客户端发起请求
- 客户端(例如浏览器)向服务器发起HTTPS请求,并发送一个包含支持的SSL/TLS协议版本、加密算法、随机数等信息的握手消息。
2. 服务器响应
- 服务器返回SSL/TLS证书,其中包含服务器的公钥和服务器身份信息(由受信任的第三方CA机构签发的数字证书)。服务器还会发送自己支持的加密算法和一个随机数。
3. 验证服务器身份
- 客户端验证服务器的数字证书是否合法(通过CA机构的公钥验证),如果证书合法,继续握手过程;如果验证失败,客户端会警告用户。
4. 生成对称密钥(会话密钥)
- 客户端生成一个新的会话密钥,然后用服务器的公钥加密这个会话密钥,并发送给服务器。由于只有服务器拥有对应的私钥,因此只有服务器可以解密并获得这个对称密钥。
5. 加密通信
- 服务器解密收到的会话密钥,客户端和服务器现在都拥有相同的对称密钥。此后,双方使用这个对称密钥通过对称加密算法(如AES)来加密和解密所有的通信内容,保证数据传输的安全性。
6. 完成握手
- 客户端和服务器确认加密的握手消息已正确接收,握手过程完成。此后,双方开始使用对称加密进行数据传输。
HTTPS加密的关键点
- 身份验证:通过服务器的数字证书(由CA签发),客户端可以确认服务器的真实身份,防止中间人攻击。
- 加密传输:利用对称加密和会话密钥,保证通信数据在传输过程中不被第三方窃听或篡改。
- 完整性校验:使用哈希函数确保数据在传输中没有被篡改。
衡量计算机网络性能的指标
衡量计算机网络性能的指标
带宽(Bandwidth)
定义:带宽是指单位时间内网络能够传输的数据量,通常以比特每秒(bps)为单位,如Mbps、Gbps等。
作用:带宽越大,网络能传输的数据量越多,意味着更高的传输能力。
时延(Latency)
定义:时延是指数据从源端到目的端的传输时间,通常以毫秒(ms)为单位。
- 类型:
- 传播时延:信号在介质中传输的时间。
- 传输时延:数据在链路上发送的时间,受带宽影响。
- 处理时延:路由器或交换机处理数据包的时间。
- 排队时延:数据在网络节点上排队等待处理的时间。
- 类型:
作用:时延越小,响应越快,适用于实时应用(如视频会议、在线游戏)。
抖动(Jitter)
定义:抖动是指连续数据包到达时间的差异,通常以毫秒(ms)为单位。
作用:抖动较大时,会导致实时性应用(如语音、视频)的质量下降,数据包可能会乱序到达。
吞吐量(Throughput)
定义:吞吐量是指单位时间内实际传输的数据量,通常以bps为单位。
作用:衡量网络实际能提供的有效数据传输能力,受带宽、网络负载、协议效率等影响。
丢包率(Packet Loss Rate)
定义:丢包率是指网络中数据包的丢失比例,通常以百分比表示。
作用:丢包率过高会影响应用的性能,尤其是对数据完整性要求较高的应用(如文件传输、视频流)影响较大。
错误率(Error Rate)
定义:错误率是指网络传输过程中出错的数据包比例,通常是因为信号干扰或网络质量问题导致的。
作用:高错误率会影响数据的完整性,导致重新传输,降低网络效率。
连接建立时间
定义:这是指从发送连接请求到成功建立连接的时间(例如TCP三次握手的时间)。
作用:对于需要频繁建立连接的应用(如HTTP请求),连接建立时间越短,用户体验越好。
网络利用率(Network Utilization)
定义:网络利用率是指网络带宽的使用率,即实际使用的带宽与可用带宽的比例。
作用:反映了网络资源的利用情况,网络利用率过高可能导致拥塞,过低则表示资源浪费。
延迟抖动(Delay Jitter)
定义:延迟抖动是指网络中时延的波动幅度,衡量时延变化的稳定性。
作用:抖动过大会影响实时应用的流畅性。
服务质量(Quality of Service,QoS)
定义:QoS是网络对不同类型流量进行优先级处理的一种机制,以确保重要的流量(如语音或视频)优先获得网络资源。
作用:通过QoS可以提高关键业务的传输效率,减少时延、抖动和丢包。
IPv4和IPv6区别
IPv4和IPv6区别
1. 地址长度
- IPv4:
- 地址长度:32位(bit),即4个字节。
- 地址表示:通常以点分十进制表示(如
192.168.0.1)。 - 地址数量:约 43亿个IP地址(2^32)。
- IPv6:
- 地址长度:128位(bit),即16个字节。
- 地址表示:通常以冒号分隔的十六进制表示(如
2001:0db8:85a3:0000:0000:8a2e:0370:7334)。 - 地址数量:约 3.4 x 10^38 个IP地址(2^128),足以满足未来需求。
2. 地址耗尽问题
- IPv4:由于互联网的迅猛发展,IPv4地址已经基本耗尽。
- IPv6:设计时考虑了地址耗尽问题,拥有几乎无限的地址空间。
3. 地址配置
- IPv4:
- 地址分配需要依赖手动配置或DHCP(动态主机配置协议)来分配。
- IPv6:
- 支持自动配置,设备可以通过无状态地址自动配置(SLAAC)自动获取IP地址,无需DHCP。
4. 路由效率
- IPv4:路由表可能比较大,尤其是随着地址耗尽使用了很多次级网络。
- IPv6:使用了更加分层和聚合的路由方式,使得路由表更加简洁,路由效率更高。
5. 内置安全性
- IPv4:安全性依赖于外部协议(如IPsec),并不是协议的一部分。
- IPv6:原生支持IPsec(Internet Protocol Security),内置了加密和身份验证机制,更加安全。
6. 广播支持
- IPv4:支持广播,允许将数据包发送到一个网络内的所有设备。
- IPv6:取消了广播,取而代之的是更高效的组播(Multicast)和任播(Anycast)。
7. 分片机制
- IPv4:在发送数据包时,路由器可以对数据包进行分片。
- IPv6:只有发送端可以进行分片,路由器不再执行分片操作,简化了路由器处理流程,提高了网络效率。
8. 头部结构
- IPv4:IPv4头部较为复杂,包含多达12个字段,大小为20-60字节。
- IPv6:IPv6头部简化,仅包含8个字段,固定为40字节,提高了处理效率。
9. NAT支持
- IPv4:由于地址不足,广泛使用NAT(网络地址转换)技术,将多个设备映射到一个公共IPv4地址。
- IPv6:由于地址充足,IPv6中无需NAT,设备可以直接拥有全局唯一的IP地址,简化了网络配置。
10. 移动性和可扩展性
- IPv6:IPv6对移动性和扩展性提供了更好的支持,尤其是在设备的无缝切换和全球路由的优化方面。
给5L和3L的无刻度量杯,如何量出4L的水
正常解
- 将3L量杯装满后倒入5L量杯
- 再将3L量杯装满后倒入已经有3L水的5L量杯里,然后把装满的5L量杯倒掉,这时3L量杯里剩1L水
- 把1L水倒进5L量杯里,再将3L量杯装满水倒入,这样就有4L水了
不正常解
两个量杯都装满水,斜着倒掉一半(水平线沿着切面对角线),全倒进5L量杯里,这样也能有4L水[doge]
得物
面向对象
特性
封装(Encapsulation)
定义:封装是将对象的属性和方法隐藏起来,不允许外部直接访问,通过公开的接口(方法)来操作数据。
作用:保证对象内部数据的安全性,避免外部随意修改对象的状态。
例子:使用
private关键字将属性设为私有,只能通过getter、setter方法访问和修改。
继承(Inheritance)
定义:继承允许一个类(子类)继承另一个类(父类)的属性和方法,子类可以复用父类的代码,也可以扩展或修改父类的行为。
作用:通过继承,可以提高代码复用性,建立类与类之间的层次结构。
例子:
Dog类可以继承Animal类,Dog类拥有Animal类的特性(如吃饭、睡觉),同时扩展出新的特性(如叫)。
多态(Polymorphism)
定义:多态是指同一个方法在不同的对象上可以有不同的表现形式,主要通过方法重写(子类实现父类方法)或方法重载(同名方法参数不同)实现。
作用:多态提高了代码的灵活性和可扩展性,可以通过同一个接口操作不同的对象,而不需要了解对象的具体类型。
例子:
Animal类的speak()方法,Dog类可以实现为“汪汪叫”,而Cat类可以实现为“喵喵叫”。
什么是AQS,有哪些类是基于AQS实现的
这个是面试官问有没有看过源码,属于是让我们自由发挥了
AQS
AQS
AQS(AbstractQueuedSynchronizer,抽象队列同步器)是Java中用于构建锁和其他同步器(如信号量、倒计时器等)的基础框架。AQS为多线程并发控制提供了一个基于FIFO(先入先出)队列的同步机制,简化了同步器的开发。
AQS的核心思想
AQS的核心是一个共享资源的状态变量(state),线程通过对该状态变量进行操作来实现对共享资源的独占或共享访问。AQS通过维护一个等待队列(即“同步队列”)来管理线程的访问顺序,分为独占模式和共享模式两种工作方式。
AQS的关键概念
- state:代表共享资源的状态,通常是一个
int类型的变量。例如在一个独占锁中,state == 0表示没有线程持有锁,state == 1表示某个线程持有了锁。 - 同步队列:AQS会维护一个FIFO队列,当线程获取锁失败时,会被加入这个队列中,以便后续再次尝试获取锁。这是线程的等待队列,类似于一种排队机制。
- 独占模式(Exclusive):某个线程独占资源。比如
ReentrantLock就是通过独占模式实现的,当一个线程持有锁时,其他线程只能进入等待队列等待。 - 共享模式(Shared):多个线程可以同时访问资源。比如
CountDownLatch和Semaphore就是基于共享模式实现的,多个线程可以共享某个资源。 - 队列节点(Node):每个线程在竞争资源失败后,会被封装为一个Node节点,加入同步队列中。Node节点主要保存线程的引用、等待状态等信息。
AQS的工作流程
- 获取锁:
- 线程尝试通过AQS提供的接口(如
acquire())获取锁,首先通过tryAcquire()尝试获取资源。 - 如果资源不可用,则将当前线程封装为一个Node节点,加入同步队列,并阻塞线程,等待资源可用时被唤醒。
- 线程尝试通过AQS提供的接口(如
- 释放锁:
- 线程释放资源时,通过
release()方法更新state状态变量。 - 如果有其他线程在等待队列中,则唤醒队列中的下一个线程,让它继续尝试获取资源。
- 线程释放资源时,通过
基于AQS实现的类
基于AQS实现的类
1. ReentrantLock
- 可重入锁,提供了公平锁和非公平锁两种实现。
- 实现原理:
ReentrantLock使用AQS的独占模式,即只有一个线程能够持有锁,其他线程需要排队等待。公平锁按请求顺序获取锁,非公平锁则允许插队。
2. Semaphore
- 信号量,用于控制同时访问某个资源的线程数。
- 实现原理:
Semaphore使用AQS的共享模式,多个线程可以同时获取信号量,最多可以允许n个线程并发执行。
3. CountDownLatch
- 倒计时器,允许一个或多个线程等待其他线程完成某些操作。
- 实现原理:
CountDownLatch也使用AQS的共享模式,通过计数器的递减操作控制线程的同步,当计数器归零时,所有等待的线程被唤醒。
4. CyclicBarrier
- 栅栏,让一组线程互相等待,直到所有线程都到达屏障点,再一起继续执行。
- 实现原理:
CyclicBarrier内部使用了一个类似于AQS的机制(基于条件队列),虽然它没有直接继承AQS,但它的工作原理与AQS类似。
5. ReadWriteLock
- 读写锁,允许多个读线程同时访问,或一个写线程独占访问。
- 实现原理:
ReentrantReadWriteLock使用AQS的独占模式和共享模式。读操作是共享模式,允许多个线程同时读取;写操作是独占模式,只有一个线程能够写入。
6. FutureTask
- 用于异步任务的执行和结果获取,它实现了
Runnable和Future接口。 - 实现原理:
FutureTask使用AQS来控制任务的状态(未启动、已启动、已完成),并确保在任务完成前,线程调用get()方法时会阻塞等待。
7. SynchronousQueue
- 同步队列,一个无容量的阻塞队列,生产者线程和消费者线程直接进行交换操作。
- 实现原理:内部使用AQS的机制来进行线程的同步和等待。
8. Exchanger
- 线程间数据交换,两个线程可以成对交换数据。
- 实现原理:类似于
SynchronousQueue,内部通过AQS进行同步控制。
9. Phaser
- 线程分阶段执行的同步器,用于管理多线程的阶段同步,类似于CyclicBarrier,但更加灵活。
- 实现原理:
Phaser内部也使用了类似于AQS的同步队列机制。
讲讲锁的升级
偏向锁(Biased Locking)
概念:
- 偏向锁是一种优化机制,假设大多数情况下,锁只会被同一个线程多次获取,因此尽量避免进行加锁的复杂操作。
锁升级过程:
- 当一个线程第一次获取锁时,JVM会将该锁对象的头部(Mark Word)记录为当前线程的ID,并标记为偏向锁状态。
- 如果没有其他线程竞争,这个线程以后每次进入同步块时,都无需真正加锁,性能非常高。
- 升级触发条件:当另一个线程尝试获取这个锁时,偏向锁会被撤销,JVM会暂停持有偏向锁的线程,清理掉偏向的标记,然后升级为轻量级锁。
适用场景:
- 偏向锁适用于无锁竞争的场景,比如单线程操作时。
轻量级锁(Lightweight Locking)
概念:
- 轻量级锁是JVM在偏向锁失效时引入的一种机制,用于避免重量级锁的高开销。它通过CAS(Compare-And-Swap)操作来实现线程之间的互斥,而不是阻塞线程。
锁升级过程:
- 当偏向锁被撤销,JVM会将锁升级为轻量级锁。轻量级锁使用CAS操作将锁对象的Mark Word替换为指向当前线程栈中的锁记录指针。
- 如果只有一个线程在竞争轻量级锁,它可以通过CAS操作成功获取锁并执行任务。
- 升级触发条件:如果有其他线程也试图获取这个轻量级锁,但CAS失败,则表示出现了锁竞争。JVM会让这些线程自旋(即不阻塞线程而等待锁的释放),如果在一定时间内锁未释放,轻量级锁将进一步升级为重量级锁。
适用场景:
- 轻量级锁适合锁竞争不激烈的场景,尤其是短暂的临界区。
重量级锁(Heavyweight Locking)
概念:
- 重量级锁是JVM使用操作系统的监视器(Monitor)机制实现的传统锁机制,当锁竞争激烈时,线程会进入阻塞状态,并通过操作系统的调度机制进行唤醒。
锁升级过程:
- 当轻量级锁竞争失败,多个线程自旋也无法获取到锁时,轻量级锁会升级为重量级锁。
- JVM会将尝试获取锁但失败的线程挂起,等待锁的释放。当持有锁的线程释放锁时,操作系统会唤醒等待队列中的线程,继续竞争该锁。
- 升级触发条件:锁竞争激烈、多个线程无法通过自旋解决竞争问题时,锁将升级为重量级锁。
适用场景:
- 重量级锁适合高并发竞争的场景,能够确保线程的互斥访问,但代价是较高的上下文切换和阻塞开销。
总结
路径
- 偏向锁 → 轻量级锁:
- 发生在锁开始出现竞争时。当一个新的线程尝试获取已经被偏向锁持有的锁时,偏向锁会撤销,并升级为轻量级锁。
- 轻量级锁 → 重量级锁:
- 发生在轻量级锁的CAS操作失败时。当多个线程尝试竞争锁,自旋等待也无法获取锁时,锁升级为重量级锁,此时会涉及线程的阻塞和唤醒。
整体过程:
- 偏向锁:没有竞争时,锁自动偏向第一个线程。
- 轻量级锁:有竞争时,通过CAS操作尝试获取锁,自旋等待短时间锁的释放。
- 重量级锁:竞争激烈时,线程阻塞进入等待队列,等待锁释放。
总结
锁的升级是为了根据不同的并发情况,动态选择更合适的同步机制,既保证程序的线程安全,又尽可能减少锁的开销。偏向锁适用于无竞争场景,轻量级锁适用于低竞争场景,重量级锁则在高并发竞争中提供强同步保障。
AOP和IOC是什么
AOP(Aspect-Oriented Programming,面向切面编程)
概念:
- AOP是一种编程范式,旨在通过分离横切关注点(cross-cutting concerns)来增强代码的可维护性和可重用性。横切关注点是指那些贯穿多个模块的通用功能,如日志记录、事务管理、安全性检查等。
- 在不修改原始业务逻辑的情况下,通过切面(Aspect)将这些功能动态地织入到代码的执行中。
核心概念:
- Aspect(切面):横切关注点的模块化封装,通常由多个通知(advice)和切点(pointcut)组成。
- Advice(通知):实际执行的代码,定义切入点发生时该执行的操作。分为前置通知、后置通知、异常通知等。
- Join Point(连接点):程序执行中的某个特定点,例如方法调用或异常抛出。
- Pointcut(切点):定义在何处应用通知的规则,通常使用表达式语言来定义。
- Weaving(织入):将切面代码动态应用到目标对象的过程。
作用:
- AOP允许我们在不改变业务逻辑代码的情况下,灵活地将某些功能注入代码执行过程,实现代码的解耦。
使用场景:
- 日志记录、事务管理、安全验证、异常处理等跨越多个模块的功能。
IOC(Inversion of Control,控制反转)
概念:
- IOC是一种设计原则,旨在将对象的创建和依赖管理交给框架(如Spring)来控制,而不是在代码中手动管理对象的生命周期和依赖关系。它的核心思想是“控制权的反转”,即由容器来管理对象的创建、依赖注入和销毁,而不是应用程序代码来处理。
实现方式:
- DI(Dependency Injection,依赖注入)是IOC的一种实现方式,通常通过构造函数注入、Setter方法注入或接口注入等方式,将对象的依赖交由IOC容器来注入。
核心概念:
- Bean:Spring管理的对象,通常由XML、注解或Java配置文件定义。
- IOC容器:管理Bean的生命周期、依赖关系和配置的容器,负责对象的创建、管理和销毁。
- 依赖注入:将对象的依赖关系通过容器注入,而不是手动在代码中创建依赖对象。
作用:
- IOC使得代码更易于测试、维护和扩展,降低了模块之间的耦合性,提高了代码的可复用性和灵活性。
使用场景:
- 任何需要管理对象依赖关系的场景,如创建复杂对象、配置服务之间的依赖等。
MySQL不同搜索引擎的索引
InnoDB
索引类型:
- 聚簇索引(Clustered Index):
- InnoDB的主键索引是聚簇索引,即数据和索引存储在一起。表中数据行的物理顺序与主键索引的顺序相同,主键索引的叶节点包含了完整的行数据。
- 如果没有定义主键,InnoDB会选择一个唯一的非空索引作为聚簇索引;如果没有这样的索引,则InnoDB会创建一个隐藏的聚簇索引。
- 二级索引(Secondary Index):
- 二级索引是非主键索引,叶节点存储主键值而非行数据。查找时,MySQL需要先通过二级索引找到主键值,然后再通过主键索引访问数据,称为“回表”操作。
- 全文索引(Full-text Index):
- 从MySQL 5.6开始,InnoDB也支持全文索引,主要用于文本字段的全文搜索。
索引结构:
- InnoDB的索引实现是基于B+树的。
- B+树是一种平衡树结构,所有叶子节点在同一层,节点按顺序存储数据并通过指针相连,查找、插入、删除的时间复杂度为O(log n)。
- 聚簇索引与二级索引都是基于B+树,但聚簇索引的叶节点存储行数据,而二级索引的叶节点存储主键值。
MyISAM
MyISAM曾经是MySQL的默认存储引擎,它不支持事务和外键,但在某些场景下读性能较好。MyISAM的索引结构与InnoDB有所不同。
MyISAM中的索引类型:
- 非聚簇索引(Non-Clustered Index):
- MyISAM的索引都是非聚簇索引,即索引和数据分开存储。索引的叶子节点存储的是指向数据文件的指针,而不是行数据本身。查找时需要通过索引找到指针,再根据指针查找数据,属于典型的“回表”操作。
- 全文索引(Full-text Index):
- MyISAM早期就支持全文索引,用于处理文本数据的搜索。
MyISAM索引结构:
- MyISAM的索引也是基于B+树实现的。
- 非聚簇索引的叶节点存储指向数据文件的文件偏移量,而不是行数据本身,这与InnoDB的聚簇索引不同。
Memory
Memory(也称为HEAP)引擎将表数据存储在内存中,适合对数据进行快速临时访问,但数据在重启后会丢失。它的索引方式与其他引擎也有所不同。
Memory中的索引类型:
- 哈希索引(Hash Index):
- Memory引擎默认使用哈希索引。哈希索引是一种基于散列函数的索引结构,可以在O(1)的时间复杂度下查找数据,适用于等值查询。
- B+树索引(B+ Tree Index):
- Memory引擎也可以使用B+树索引,但需要显式指定。适用于范围查询和排序操作。
Memory索引结构:
- 哈希索引通过散列函数将键映射到内存中的特定位置,查找速度非常快,但不适合范围查询。
- B+树索引则与InnoDB、MyISAM中的B+树索引类似,适用于范围查询。
其他引擎
Archive引擎:
- Archive引擎主要用于存储大批量的历史归档数据,它的索引功能非常有限,只支持基本的压缩数据存储和无索引的全表扫描。
NDB引擎:
- NDB(Network Database)是MySQL Cluster的存储引擎,适用于分布式集群环境。NDB引擎支持哈希索引和B+树索引,适合高并发和大规模分布式数据处理。
Redis为什么高性能
Redis为什么高性能
纯内存操作
内存存储:Redis将所有数据存储在内存中,避免了磁盘I/O的瓶颈。由于内存的读写速度远远快于磁盘,Redis的操作可以在毫秒级甚至微秒级完成。
内存效率:Redis的数据结构设计高度优化,能够在内存中存储尽可能多的数据,并且使用不同的编码来压缩数据,减少内存占用。
单线程模型
单线程架构:Redis采用单线程模型来处理所有的客户端请求,避免了多线程中的上下文切换、锁竞争等问题,从而减少了处理请求的开销。
非阻塞I/O:Redis使用非阻塞的I/O复用机制,如
epoll,允许单个线程高效地处理大量客户端连接。
高效的数据结构
- Redis支持多种复杂的数据结构,如字符串、哈希表、列表、集合、排序集合等。每种数据结构都经过高度优化,以适应快速存取的需求。
- 跳表(Skip List):用于实现排序集合(Sorted Set),在范围查询和排序操作上效率非常高。
- 压缩列表(Ziplist):一种用于小规模哈希表和列表的内存优化数据结构。
- 整数集合(Intset):存储整数类型的集合,进一步减少内存开销。
- Redis支持多种复杂的数据结构,如字符串、哈希表、列表、集合、排序集合等。每种数据结构都经过高度优化,以适应快速存取的需求。
I/O多路复用
- Redis使用了I/O多路复用技术(如
select、epoll),允许一个线程同时处理多个客户端请求。这种机制使Redis能够高效地处理数千个并发连接,同时保证请求响应速度。
- Redis使用了I/O多路复用技术(如
数据持久化机制
虽然Redis将数据存储在内存中,但它提供了多种持久化机制,以确保数据的安全性:
- RDB(Redis Database Backup):通过定期生成数据快照,将数据写入磁盘。
AOF(Append Only File):将每个写操作记录到日志文件中,保证数据在系统重启后不丢失。
这种设计使Redis既能保持高性能,又能通过合理的持久化策略保证数据的安全。
高效的通信协议
- Redis设计了非常轻量级的二进制协议,称为RESP(Redis Serialization Protocol),该协议简单高效,能够快速解析和传输数据,进一步提升了数据交互性能。
高效的分布式集群架构
- Redis支持主从复制和分片(Sharding),通过集群分布式部署扩展系统的读写性能。主从复制提高了读取的并发能力,而分片通过将数据分布到多个节点上,减轻了单个节点的压力,提升了系统的整体性能。
支持管道(Pipelining)
- Redis支持管道操作,允许客户端将多个命令一起发送给服务器,而不必等待每个命令执行后的响应,从而减少网络延迟和交互次数,极大地提高了吞吐量。
结语
终于整理完了,累死了,搞这玩意加了我4天班,终于赶在中秋节前水出来了。
面试最主要还是能扯,不要怕说错,把你思考的过程表现出来,就算面试官说这个可以怎样怎样,你也可以追着反问他。
还有就是谈薪的时候在你的期望上(一定是期望,不要被历年的薪资误导了)高个20%~30%,不然会后悔的😭😭😭
 微信
微信 支付宝
支付宝






